- Distributed computing
-
Distributed computing is a field of computer science that studies distributed systems. A distributed system consists of multiple autonomous computers that communicate through a computer network. The computers interact with each other in order to achieve a common goal. A computer program that runs in a distributed system is called a distributed program, and distributed programming is the process of writing such programs.[1]
Distributed computing also refers to the use of distributed systems to solve computational problems. In distributed computing, a problem is divided into many tasks, each of which is solved by one or more computers.[2]
Contents
Introduction
The word distributed in terms such as "distributed system", "distributed programming", and "distributed algorithm" originally referred to computer networks where individual computers were physically distributed within some geographical area.[3] The terms are nowadays used in a much wider sense, even referring to autonomous processes that run on the same physical computer and interact with each other by message passing.[4]
While there is no single definition of a distributed system,[5] the following defining properties are commonly used:
- There are several autonomous computational entities, each of which has its own local memory.[6]
- The entities communicate with each other by message passing.[7]
In this article, the computational entities are called computers or nodes.
A distributed system may have a common goal, such as solving a large computational problem.[8] Alternatively, each computer may have its own user with individual needs, and the purpose of the distributed system is to coordinate the use of shared resources or provide communication services to the users.[9]
Other typical properties of distributed systems include the following:
- The system has to tolerate failures in individual computers.[10]
- The structure of the system (network topology, network latency, number of computers) is not known in advance, the system may consist of different kinds of computers and network links, and the system may change during the execution of a distributed program.[11]
- Each computer has only a limited, incomplete view of the system. Each computer may know only one part of the input.[12]
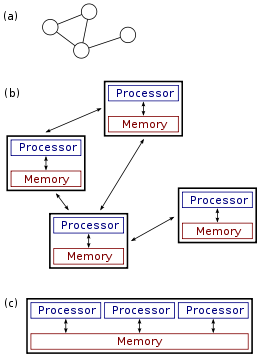 (a)–(b) A distributed system.
(a)–(b) A distributed system.
(c) A parallel system.Parallel and distributed computing
Distributed systems are groups of networked computers, which have the same goal for their work. The terms "concurrent computing", "parallel computing", and "distributed computing" have a lot of overlap, and no clear distinction exists between them.[13] The same system may be characterised both as "parallel" and "distributed"; the processors in a typical distributed system run concurrently in parallel.[14] Parallel computing may be seen as a particular tightly-coupled form of distributed computing,[15] and distributed computing may be seen as a loosely-coupled form of parallel computing.[5] Nevertheless, it is possible to roughly classify concurrent systems as "parallel" or "distributed" using the following criteria:
- In parallel computing, all processors have access to a shared memory. Shared memory can be used to exchange information between processors.[16]
- In distributed computing, each processor has its own private memory (distributed memory). Information is exchanged by passing messages between the processors.[17]
The figure on the right illustrates the difference between distributed and parallel systems. Figure (a) is a schematic view of a typical distributed system; as usual, the system is represented as a network topology in which each node is a computer and each line connecting the nodes is a communication link. Figure (b) shows the same distributed system in more detail: each computer has its own local memory, and information can be exchanged only by passing messages from one node to another by using the available communication links. Figure (c) shows a parallel system in which each processor has a direct access to a shared memory.
The situation is further complicated by the traditional uses of the terms parallel and distributed algorithm that do not quite match the above definitions of parallel and distributed systems; see the section Theoretical foundations below for more detailed discussion. Nevertheless, as a rule of thumb, high-performance parallel computation in a shared-memory multiprocessor uses parallel algorithms while the coordination of a large-scale distributed system uses distributed algorithms.
History
The use of concurrent processes that communicate by message-passing has its roots in operating system architectures studied in the 1960s.[18] The first widespread distributed systems were local-area networks such as Ethernet that was invented in the 1970s.[19]
ARPANET, the predecessor of the Internet, was introduced in the late 1960s, and ARPANET e-mail was invented in the early 1970s. E-mail became the most successful application of ARPANET,[20] and it is probably the earliest example of a large-scale distributed application. In addition to ARPANET, and its successor, the Internet, other early worldwide computer networks included Usenet and FidoNet from 1980s, both of which were used to support distributed discussion systems.
The study of distributed computing became its own branch of computer science in the late 1970s and early 1980s. The first conference in the field, Symposium on Principles of Distributed Computing (PODC), dates back to 1982, and its European counterpart International Symposium on Distributed Computing (DISC) was first held in 1985.
Applications
There are two main reasons for using distributed systems and distributed computing. First, the very nature of the application may require the use of a communication network that connects several computers. For example, data is produced in one physical location and it is needed in another location.
Second, there are many cases in which the use of a single computer would be possible in principle, but the use of a distributed system is beneficial for practical reasons. For example, it may be more cost-efficient to obtain the desired level of performance by using a cluster of several low-end computers, in comparison with a single high-end computer. A distributed system can be more reliable than a non-distributed system, as there is no single point of failure. Moreover, a distributed system may be easier to expand and manage than a monolithic uniprocessor system.[21]
Examples of distributed systems and applications of distributed computing include the following:[22]
- Telecommunication networks:
- Telephone networks and cellular networks.
- Computer networks such as the Internet.
- Wireless sensor networks.
- Routing algorithms.
- Network applications:
- World wide web and peer-to-peer networks.
- Massively multiplayer online games and virtual reality communities.
- Distributed databases and distributed database management systems.
- Network file systems.
- Distributed information processing systems such as banking systems and airline reservation systems.
- Real-time process control:
- Aircraft control systems.
- Industrial control systems.
- Parallel computation:
- Scientific computing, including cluster computing and grid computing and various volunteer computing projects; see the list of distributed computing projects.
- Distributed rendering in computer graphics.
Theoretical foundations
Main article: Distributed algorithmModels
Many tasks that we would like to automate by using a computer are of question–answer type: we would like to ask a question and the computer should produce an answer. In theoretical computer science, such tasks are called computational problems. Formally, a computational problem consists of instances together with a solution for each instance. Instances are questions that we can ask, and solutions are desired answers to these questions.
Theoretical computer science seeks to understand which computational problems can be solved by using a computer (computability theory) and how efficiently (computational complexity theory). Traditionally, it is said that a problem can be solved by using a computer if we can design an algorithm that produces a correct solution for any given instance. Such an algorithm can be implemented as a computer program that runs on a general-purpose computer: the program reads a problem instance from input, performs some computation, and produces the solution as output. Formalisms such as random access machines or universal Turing machines can be used as abstract models of a sequential general-purpose computer executing such an algorithm.
The field of concurrent and distributed computing studies similar questions in the case of either multiple computers, or a computer that executes a network of interacting processes: which computational problems can be solved in such a network and how efficiently? However, it is not at all obvious what is meant by “solving a problem” in the case of a concurrent or distributed system: for example, what is the task of the algorithm designer, and what is the concurrent or distributed equivalent of a sequential general-purpose computer?
The discussion below focusses on the case of multiple computers, although many of the issues are the same for concurrent processes running on a single computer.
Three viewpoints are commonly used:
- Parallel algorithms in shared-memory model
- All computers have access to a shared memory. The algorithm designer chooses the program executed by each computer.
- One theoretical model is the parallel random access machines (PRAM) that are used.[23] However, the classical PRAM model assumes synchronous access to the shared memory.
- A model that is closer to the behavior of real-world multiprocessor machines and takes into account the use of machine instructions, such as Compare-and-swap (CAS), is that of asynchronous shared memory. There is a wide body of work on this model, a summary of which can be found in the literature.[24][25]
- Parallel algorithms in message-passing model
- The algorithm designer chooses the structure of the network, as well as the program executed by each computer.
- Models such as Boolean circuits and sorting networks are used.[26] A Boolean circuit can be seen as a computer network: each gate is a computer that runs an extremely simple computer program. Similarly, a sorting network can be seen as a computer network: each comparator is a computer.
- Distributed algorithms in message-passing model
- The algorithm designer only chooses the computer program. All computers run the same program. The system must work correctly regardless of the structure of the network.
- A commonly used model is a graph with one finite-state machine per node.
In the case of distributed algorithms, computational problems are typically related to graphs. Often the graph that describes the structure of the computer network is the problem instance. This is illustrated in the following example.
An example
Consider the computational problem of finding a coloring of a given graph G. Different fields might take the following approaches:
- Centralized algorithms
- The graph G is encoded as a string, and the string is given as input to a computer. The computer program finds a coloring of the graph, encodes the coloring as a string, and outputs the result.
- Parallel algorithms
- Again, the graph G is encoded as a string. However, multiple computers can access the same string in parallel. Each computer might focus on one part of the graph and produce a colouring for that part.
- The main focus is on high-performance computation that exploits the processing power of multiple computers in parallel.
- Distributed algorithms
- The graph G is the structure of the computer network. There is one computer for each node of G and one communication link for each edge of G. Initially, each computer only knows about its immediate neighbours in the graph G; the computers must exchange messages with each other to discover more about the structure of G. Each computer must produce its own colour as output.
- The main focus is on coordinating the operation of an arbitrary distributed system.
While the field of parallel algorithms has a different focus than the field of distributed algorithms, there is a lot of interaction between the two fields. For example, the Cole–Vishkin algorithm for graph colouring[27] was originally presented as a parallel algorithm, but the same technique can also be used directly as a distributed algorithm.
Moreover, a parallel algorithm can be implemented either in a parallel system (using shared memory) or in a distributed system (using message passing).[28] The traditional boundary between parallel and distributed algorithms (choose a suitable network vs. run in any given network) does not lie in the same place as the boundary between parallel and distributed systems (shared memory vs. message passing).
Complexity measures
In parallel algorithms, yet another resource in addition to time and space is the number of computers. Indeed, often there is a trade-off between the running time and the number of computers: the problem can be solved faster if there are more computers running in parallel (see speedup). If a decision problem can be solved in polylogarithmic time by using a polynomial number of processors, then the problem is said to be in the class NC.[29] The class NC can be defined equally well by using the PRAM formalism or Boolean circuits – PRAM machines can simulate Boolean circuits efficiently and vice versa.[30]
In the analysis of distributed algorithms, more attention is usually paid on communication operations than computational steps. Perhaps the simplest model of distributed computing is a synchronous system where all nodes operate in a lockstep fashion. During each communication round, all nodes in parallel (1) receive the latest messages from their neighbours, (2) perform arbitrary local computation, and (3) send new messages to their neighbours. In such systems, a central complexity measure is the number of synchronous communication rounds required to complete the task.[31]
This complexity measure is closely related to the diameter of the network. Let D be the diameter of the network. On the one hand, any computable problem can be solved trivially in a synchronous distributed system in approximately 2D communication rounds: simply gather all information in one location (D rounds), solve the problem, and inform each node about the solution (D rounds).
On the other hand, if the running time of the algorithm is much smaller than D communication rounds, then the nodes in the network must produce their output without having the possibility to obtain information about distant parts of the network. In other words, the nodes must make globally consistent decisions based on information that is available in their local neighbourhood. Many distributed algorithms are known with the running time much smaller than D rounds, and understanding which problems can be solved by such algorithms is one of the central research questions of the field.[32]
Other commonly used measures are the total number of bits transmitted in the network (cf. communication complexity).
Other problems
Traditional computational problems take the perspective that we ask a question, a computer (or a distributed system) processes the question for a while, and then produces an answer and stops. However, there are also problems where we do not want the system to ever stop. Examples of such problems include the dining philosophers problem and other similar mutual exclusion problems. In these problems, the distributed system is supposed to continuously coordinate the use of shared resources so that no conflicts or deadlocks occur.
There are also fundamental challenges that are unique to distributed computing. The first example is challenges that are related to fault-tolerance. Examples of related problems include consensus problems,[33] Byzantine fault tolerance,[34] and self-stabilisation.[35]
A lot of research is also focused on understanding the asynchronous nature of distributed systems:
- Synchronizers can be used to run synchronous algorithms in asynchronous systems.[36]
- Logical clocks provide a causal happened-before ordering of events.[37]
- Clock synchronization algorithms provide globally consistent physical time stamps.[38]
Properties of distributed systems
So far the focus has been on designing a distributed system that solves a given problem. A complementary research problem is studying the properties of a given distributed system.
The halting problem is an analogous example from the field of centralised computation: we are given a computer program and the task is to decide whether it halts or runs forever. The halting problem is undecidable in the general case, and naturally understanding the behaviour of a computer network is at least as hard as understanding the behaviour of one computer.
However, there are many interesting special cases that are decidable. In particular, it is possible to reason about the behaviour of a network of finite-state machines. One example is telling whether a given network of interacting (asynchronous and non-deterministic) finite-state machines can reach a deadlock. This problem is PSPACE-complete,[39] i.e., it is decidable, but it is not likely that there is an efficient (centralised, parallel or distributed) algorithm that solves the problem in the case of large networks.
Architectures
Various hardware and software architectures are used for distributed computing. At a lower level, it is necessary to interconnect multiple CPUs with some sort of network, regardless of whether that network is printed onto a circuit board or made up of loosely-coupled devices and cables. At a higher level, it is necessary to interconnect processes running on those CPUs with some sort of communication system.
Distributed programming typically falls into one of several basic architectures or categories: client–server, 3-tier architecture, n-tier architecture, distributed objects, loose coupling, or tight coupling.
- Client–server: Smart client code contacts the server for data then formats and displays it to the user. Input at the client is committed back to the server when it represents a permanent change.
- 3-tier architecture: Three tier systems move the client intelligence to a middle tier so that stateless clients can be used. This simplifies application deployment. Most web applications are 3-Tier.
- n-tier architecture: n-tier refers typically to web applications which further forward their requests to other enterprise services. This type of application is the one most responsible for the success of application servers.
- Tightly coupled (clustered): refers typically to a cluster of machines that closely work together, running a shared process in parallel. The task is subdivided in parts that are made individually by each one and then put back together to make the final result.
- Peer-to-peer: an architecture where there is no special machine or machines that provide a service or manage the network resources. Instead all responsibilities are uniformly divided among all machines, known as peers. Peers can serve both as clients and servers.
- Space based: refers to an infrastructure that creates the illusion (virtualization) of one single address-space. Data are transparently replicated according to application needs. Decoupling in time, space and reference is achieved.
Another basic aspect of distributed computing architecture is the method of communicating and coordinating work among concurrent processes. Through various message passing protocols, processes may communicate directly with one another, typically in a master/slave relationship. Alternatively, a "database-centric" architecture can enable distributed computing to be done without any form of direct inter-process communication, by utilizing a shared database.[40]
See also
- List of important publications in concurrent, parallel, and distributed computing
- Edsger W. Dijkstra Prize in Distributed Computing
- List of distributed computing conferences
- List of distributed computing projects
- Parallel distributed processing
- Parallel programming model
- Volunteer computing
- BOINC
Notes
- ^ Andrews (2000). Dolev (2000). Ghosh (2007), p. 10.
- ^ Godfrey (2002).
- ^ Lynch (1996), p. 1.
- ^ Andrews (2000), p. 291–292. Dolev (2000), p. 5.
- ^ a b Ghosh (2007), p. 10.
- ^ Andrews (2000), p. 8–9, 291. Dolev (2000), p. 5. Ghosh (2007), p. 3. Lynch (1996), p. xix, 1. Peleg (2000), p. xv.
- ^ Andrews (2000), p. 291. Ghosh (2007), p. 3. Peleg (2000), p. 4.
- ^ Ghosh (2007), p. 3–4. Peleg (2000), p. 1.
- ^ Ghosh (2007), p. 4. Peleg (2000), p. 2.
- ^ Ghosh (2007), p. 4, 8. Lynch (1996), p. 2–3. Peleg (2000), p. 4.
- ^ Lynch (1996), p. 2. Peleg (2000), p. 1.
- ^ Ghosh (2007), p. 7. Lynch (1996), p. xix, 2. Peleg (2000), p. 4.
- ^ Ghosh (2007), p. 10. Keidar (2008).
- ^ Lynch (1996), p. xix, 1–2. Peleg (2000), p. 1.
- ^ Peleg (2000), p. 1.
- ^ Papadimitriou (1994), Chapter 15. Keidar (2008).
- ^ See references in Introduction.
- ^ Andrews (2000), p. 348.
- ^ Andrews (2000), p. 32.
- ^ Peter (2004), The history of email.
- ^ Elmasri & Navathe (2000), Section 24.1.2.
- ^ Andrews (2000), p. 10–11. Ghosh (2007), p. 4–6. Lynch (1996), p. xix, 1. Peleg (2000), p. xv. Elmasri & Navathe (2000), Section 24.
- ^ Cormen, Leiserson & Rivest (1990), Section 30.
- ^ Herlihy & Shavit (2008), Chapters 2-6.
- ^ Lynch (1996)
- ^ Cormen, Leiserson & Rivest (1990), Sections 28 and 29.
- ^ Cole & Vishkin (1986). Cormen, Leiserson & Rivest (1990), Section 30.5.
- ^ Andrews (2000), p. ix.
- ^ Arora & Barak (2009), Section 6.7. Papadimitriou (1994), Section 15.3.
- ^ Papadimitriou (1994), Section 15.2.
- ^ Lynch (1996), p. 17–23.
- ^ Peleg (2000), Sections 2.3 and 7. Linial (1992). Naor & Stockmeyer (1995).
- ^ Lynch (1996), Sections 5–7. Ghosh (2007), Chapter 13.
- ^ Lynch (1996), p. 99–102. Ghosh (2007), p. 192–193.
- ^ Dolev (2000). Ghosh (2007), Chapter 17.
- ^ Lynch (1996), Section 16. Peleg (2000), Section 6.
- ^ Lynch (1996), Section 18. Ghosh (2007), Sections 6.2–6.3.
- ^ Ghosh (2007), Section 6.4.
- ^ Papadimitriou (1994), Section 19.3.
- ^ Lind P, Alm M (2006), "A database-centric virtual chemistry system", J Chem Inf Model 46 (3): 1034–9, doi:10.1021/ci050360b, PMID 16711722.
References
- Books
- Andrews, Gregory R. (2000), Foundations of Multithreaded, Parallel, and Distributed Programming, Addison–Wesley, ISBN 0-201-35752-6.
- Arora, Sanjeev; Barak, Boaz (2009), Computational Complexity – A Modern Approach, Cambridge, ISBN 978-0-521-42426-4.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L. (1990), Introduction to Algorithms (1st ed.), MIT Press, ISBN 0-262-03141-8.
- Dolev, Shlomi (2000), Self-Stabilization, MIT Press, ISBN 0-262-04178-2.
- .
- Ghosh, Sukumar (2007), Distributed Systems – An Algorithmic Approach, Chapman & Hall/CRC, ISBN 978-1-58488-564-1.
- Lynch, Nancy A. (1996), Distributed Algorithms, Morgan Kaufmann, ISBN 1-55860-348-4.
- Herlihy, Maurice P.; Shavit, Nir N. (2008), The Art of Multiprocessor Programming, Morgan Kaufmann, ISBN 0-12-370591-6.
- Papadimitriou, Christos H. (1994), Computational Complexity, Addison–Wesley, ISBN 0-201-53082-1.
- Peleg, David (2000), Distributed Computing: A Locality-Sensitive Approach, SIAM, ISBN 0-89871-464-8, http://www.ec-securehost.com/SIAM/DT05.html.
- Articles
- Cole, Richard; Vishkin, Uzi (1986), "Deterministic coin tossing with applications to optimal parallel list ranking", Information and Control 70 (1): 32–53, doi:10.1016/S0019-9958(86)80023-7.
- Keidar, Idit (2008), "Distributed computing column 32 – The year in review", ACM SIGACT News 39 (4): 53–54, doi:10.1145/1466390.1466402, http://webee.technion.ac.il/~idish/sigactNews/#column%2032.
- Linial, Nathan (1992), "Locality in distributed graph algorithms", SIAM Journal on Computing 21 (1): 193–201, doi:10.1137/0221015.
- Naor, Moni; Stockmeyer, Larry (1995), "What can be computed locally?", SIAM Journal on Computing 24 (6): 1259–1277, doi:10.1137/S0097539793254571.
- Web sites
- Godfrey, Bill (2002). "A primer on distributed computing". http://www.bacchae.co.uk/docs/dist.html.
- Peter, Ian (2004). "Ian Peter's History of the Internet". http://www.nethistory.info/History%20of%20the%20Internet/. Retrieved 2009-08-04.
Further reading
- Books
- Attiya, Hagit and Welch, Jennifer (2004), Distributed Computing: Fundamentals, Simulations, and Advanced Topics, Wiley-Interscience ISBN 0471453242.
- Faber, Jim (1998), Java Distributed Computing, O'Reilly, http://docstore.mik.ua/orelly/java-ent/dist/index.htm: Java Distributed Computing by Jim Faber, 1998
- Garg, Vijay K. (2002), Elements of Distributed Computing, Wiley-IEEE Press ISBN 0471036005.
- Tel, Gerard (1994), Introduction to Distributed Algorithms, Cambridge University Press
- Articles
- Keidar, Idit; Rajsbaum, Sergio, eds. (2000–2009), "Distributed computing column", ACM SIGACT News, http://webee.technion.ac.il/~idish/sigactNews/.
- Birrell, A. D.; Levin, R.; Schroeder, M. D.; Needham, R. M. (April 1982). "Grapevine: An exercise in distributed computing". Communications of the ACM 25 (4): 260–274. doi:10.1145/358468.358487. http://www.cs.ucsb.edu/~ravenben/papers/coreos/BLS+82.pdf.
- Conference Papers
- C. Rodríguez, M. Villagra and B. Barán, Asynchronous team algorithms for Boolean Satisfiability, Bionetics2007, pp. 66–69, 2007.
External links
- Distributed computing at the Open Directory Project
- Distributed computing journals at the Open Directory Project
Parallel computing General Cloud computing · High-performance computing · Cluster computing · Distributed computing · Grid computing
Levels Threads Theory Elements Coordination Multiprocessing · Multithreading (computer architecture) · Memory coherency · Cache coherency · Cache invalidation · Barrier · Synchronization · Application checkpointingProgramming Hardware Multiprocessor (Symmetric · Asymmetric) · Memory (NUMA · COMA · distributed · shared · distributed shared) · SMT
MPP · Superscalar · Vector processor · Supercomputer · BeowulfAPIs Ateji PX · POSIX Threads · OpenMP · OpenHMPP · PVM · MPI · UPC · Intel Threading Building Blocks · Boost.Thread · Global Arrays · Charm++ · Cilk · Co-array Fortran · OpenCL · CUDA · Dryad · DryadLINQProblems Embarrassingly parallel · Grand Challenge · Software lockout · Scalability · Race conditions · Deadlock · Livelock · Deterministic algorithm · Parallel slowdown
Categories:


Wikimedia Foundation. 2010.