- Method of conditional probabilities
-
In mathematics and computer science, the probabilistic method is used to prove the existence of mathematical objects with desired combinatorial properties. The proofs are probabilistic — they work by showing that a random object, chosen from some probability distribution, has the desired properties with positive probability. Consequently, they are nonconstructive — they don't explicitly describe an efficient method for computing the desired objects.
The method of conditional probabilities (Erdös & Selfridge 1973), (Spencer 1987), (Raghavan 1988) converts such a proof, in a "very precise sense", into an efficient deterministic algorithm, one that is guaranteed to compute an object with the desired properties. That is, the method derandomizes the proof. The basic idea is to replace each random choice in a random experiment by a deterministic choice, so as to keep the conditional probability of failure, given the choices so far, below 1.
The method is particularly relevant in the context of randomized rounding (which uses the probabilistic method to design approximation algorithms).
When applying the method of conditional probabilities, the technical term pessimistic estimator refers to a quantity used in place of the true conditional probability (or conditional expectation) underlying the proof.
Contents
Overview
(Raghavan 1988) gives this description:
- We first show the existence of a provably good approximate solution using the probabilistic method... [We then] show that the probabilistic existence proof can be converted, in a very precise sense, into a deterministic approximation algorithm.
(Raghavan is discussing the method in the context of randomized rounding, but it works with the probabilistic method in general.)
 The method of conditional probabilities
The method of conditional probabilities
To apply the method to a probabilistic proof, the randomly chosen object in the proof must be choosable by a random experiment that consists of a sequence of "small" random choices.
Here is a trivial example to illustrate the principle.
- Lemma: It is possible to flip three coins so that the number of tails is at least 2.
- Probabilistic proof. If the three coins are flipped randomly, the expected number of tails is 1.5. Thus, there must be some outcome (way of flipping the coins) so that the number of tails is at least 1.5. Since the number of tails is an integer, in such an outcome there are at least 2 tails. QED
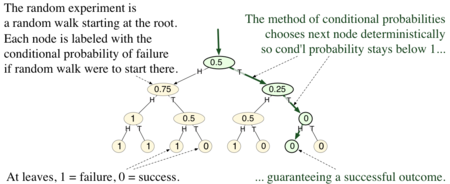
In this example the random experiment consists of flipping three fair coins. The experiment is illustrated by the rooted tree in the diagram to the right. There are eight outcomes, each corresponding to a leaf in the tree. A trial of the random experiment corresponds to taking a random walk from the root (the top node in the tree, where no coins have been flipped) to a leaf. The successful outcomes are those in which at least two coins came up tails. The interior nodes in the tree correspond to partially determined outcomes, where only 0, 1, or 2 of the coins have been flipped so far.
To apply the method of conditional probabilities, one focuses on the conditional probability of failure, given the choices so far as the experiment proceeds step by step. In the diagram, each node is labeled with this conditional probability. (For example, if only the first coin has been flipped, and it comes up tails, that corresponds to the second child of the root. Conditioned on that partial state, the probability of failure is 0.25.)
The method of conditional probabilities replaces the random root-to-leaf walk in the random experiment by a deterministic root-to-leaf walk, where each step is chosen to inductively maintain the following invariant:
-
- the conditional probability of failure, given the current state, is less than 1.
In this way, it is guaranteed to arrive at a leaf with label 0, that is, a successful outcome.
The invariant holds initially (at the root), because the original proof showed that the (unconditioned) probability of failure is less than 1. The conditional probability at any interior node is the average of the conditional probabilities of its children. The latter property is important because it implies that any interior node whose conditional probability is less than 1 has at least one child whose conditional probability is less than 1. Thus, from any interior node, one can always choose some child to walk to so as to maintain the invariant. Since the invariant holds at the end, when the walk arrives at a leaf and all choices have been determined, the outcome reached in this way must be a successful one.
Efficiency
In a typical application of the method, the goal is to be able to implement the resulting deterministic process by a reasonably efficient algorithm (formally, one taking time polynomial in the input size), even though typically the number of possible outcomes is huge (exponentially large). (E.g., consider the example above, but extended to n flips for large n.)
In the ideal case, given a partial state (a node in the tree), the conditional probability of failure (the label on the node) can be efficiently and exactly computed. (The example above is like this.) If this is so, then the algorithm can select the next node to go to by computing the conditional probabilities at each of the children of the current node, then moving to any child whose conditional probability is less than 1. As discussed above, there is guaranteed to be such a node.
Unfortunately, in most applications, the conditional probability of failure is not easy to compute efficiently. There are two standard and related techniques for dealing with this:
- Using a conditional expectation: Many probabilistic proofs work as follows: they implicitly define a random variable Q, show that (i) the expectation of Q is at most (or at least) some threshold value, and (ii) in any outcome where Q is at most (at least) this threshold, the outcome is a success. Then (i) implies that there exists an outcome where Q is at most the threshold, and this and (ii) imply that there is an outcome that is a success. (In the example above, Q is the number of tails, which should be at least the threshold 1.5. In many applications, Q is the number of "bad" events (not necessarily disjoint) that occur in a given outcome, where each bad event corresponds to one way the experiment can fail, and the expected number of bad events that occur is less than 1.)
In this case, to keep the conditional probability of failure below 1, it suffices to keep the conditional expectation of Q below (or above) the threshold. To do this, instead of computing the conditional probability of failure, the algorithm computes the conditional expectation of Q and proceeds accordingly: at each interior node, there is some child whose conditional expectation is at most (at least) the node's conditional expectation; the algorithm moves from the current node to such a child, thus keeping the conditional expectation below (above) the threshold.
- Using a pessimistic estimator: In some cases, as a proxy for the exact conditional expectation of the quantity Q, one uses an appropriately tight bound called a pessimistic estimator. The pessimistic estimator is a function of the current state. It should upper (or lower) bound the conditional expectation of Q given the current state, and it should be non-increasing (or non-decreasing) in expectation with each random step of the experiment. Typically, a good pessimistic estimator can be computed by precisely deconstructing the logic of the original proof.
Example using conditional expectations
This example demonstrates the method of conditional probabilities using a conditional expectation.
Max-Cut Lemma
Given any undirected graph G = (V,E), the Max cut problem is to color each vertex of the graph with one of two colors (say black or white) so as to maximize the number of edges whose endpoints have different colors. (Say such an edge is cut.)
Lemma: In any graph G = (V,E), at least | E | / 2 edges can be cut.
Probabilistic proof of Max-Cut lemma
Color each vertex black or white by flipping a fair coin. By calculation, for any edge e in E, the probability that it is cut is 1/2. Thus, by linearity of expectation, the expected number of edges cut is | E | / 2. Thus, there exists a coloring that cuts at least | E | / 2 edges. QED
The method of conditional probabilities with conditional expectations
To apply the method of conditional probabilities, first model the random experiment as a sequence of small random steps. In this case it is natural to consider each step to be the choice of color for a particular vertex (so there are | V | steps).
Next, replace the random choice at each step by a deterministic choice, so as to keep the conditional probability of failure, given the vertices colored so far, below 1. (Here failure means that finally fewer than | E | / 2 edges are cut.)
In this case, the conditional probability of failure is not easy to calculate (indeed the original proof did not calculate the probability of failure directly). Instead, the proof worked by showing that the expected number of cut edges was at least | E | / 2.
Let random variable Q be the number of edges cut. To keep the conditional probability of failure below 1, it suffices to keep the conditional expectation of Q at or above the threshold | E | / 2. (This is because as long as the conditional expectation of Q is at least | E | / 2, there must be some still-reachable outcome where Q is at least | E | / 2, so the conditional probability of reaching such an outcome is positive.) To keep the conditional expectation of Q at | E | / 2 or above, the algorithm will, at each step, color the vertex under consideration so as to maximize the resulting conditional expectation of Q. This suffices, because there must be some child whose conditional expectation is at least the current state's conditional expectation (and thus at least | E | / 2).
Given that some of the vertices are colored already, what is this conditional expectation? Following the logic of the original proof, the conditional expectation of the number of cut edges is
-
- the number of edges whose endpoints are colored differently so far
- + (1/2)*(the number of edges with at least one endpoint not yet colored).
Algorithm
The algorithm colors each vertex to maximize the resulting value of the above conditional expectation. This is guaranteed to keep the conditional expectation at | E | / 2 or above, and so is guaranteed to keep the conditional probability of failure below 1, which in turn guarantees a successful outcome. By calculation, the algorithm simplifies to the following:
1. For each vertex u in V (in any order): 2. Consider the already-colored neighboring vertices of u. 3. If more of these are black then white, then color u white. 4. Otherwise, color u black.
Because of its derivation, this deterministic algorithm is guaranteed to cut at least half the edges of the given graph. (This makes it a 0.5-approximation algorithm for Max-cut.)
Example using pessimistic estimators
The next example demonstrates the use of pessimistic estimators.
Turán's theorem
One way of stating Turán's theorem is the following:
- Any graph G = (V,E) contains an independent set of size at least | V | / (D + 1), where D = 2 | E | / | V | is the average degree of the graph.
Probabilistic proof of Turan's theorem
Consider the following random process for constructing an independent set S:
1. Initialize S to be the empty set. 2. For each vertex u in V in random order: 3. If no neighbors of u are in S, add u to S 4. Return S.
Clearly the process computes an independent set. Any vertex u that is considered before all of its neighbors will be added to S. Thus, letting d(u) denote the degree of u, the probability that u is added to S is at least 1 / (d(u) + 1). By linearity of expectation, the expected size of S is at least
(The inequality above follows because 1 / (x + 1) is convex in x, so the left-hand side is minimized, subject to the sum of the degrees being fixed at 2 | E | , when each d(u) = D = 2 | E | / | V | .) QED
The method of conditional probabilities using pessimistic estimators
In this case, the random process has | V | steps. Each step considers some not-yet considered vertex u and adds u to S if none of its neighbors have yet been added. Let random variable Q be the number of vertices added to S. The proof shows that E[Q] ≥ | V | / (D + 1).
We will replace each random step by a deterministic step that keeps the conditional expectation of Q at or above | V | / (D + 1). This will ensure a successful outcome, that is, one in which the independent set S has size at least | V | / (D + 1), realizing the bound in Turan's theorem.
Given that the first t steps have been taken, let S(t) denote the vertices added so far. Let R(t) denote those vertices that have not yet been considered, and that have no neighbors in S(t). Given the first t steps, following the reasoning in the original proof, any given vertex w in R(t) has conditional probability at least 1 / (d(w) + 1) of being added to S, so the conditional expectation of Q is at least
Let Q(t) denote the above quantity, which is called a pessimistic estimator for the conditional expectation.
The proof showed that the pessimistic estimator is initially at least | V | / (D + 1). (That is, Q(0) ≥ | V | / (D + 1).) The algorithm will make each choice to keep the pessimistic estimator from decreasing, that is, so that Q(t + 1) ≥ Q(t) for each t. Since the pessimistic estimator is a lower bound on the conditional expectation, this will ensure that the conditional expectation stays above | V | / (D + 1), which in turn will ensure that the conditional probability of failure stays below 1.
Let u be the vertex considered by the algorithm in the next (t + 1st) step.
If u already has a neighbor in S, then u is not added to S and (by inspection of Q(t)), the pessimistic estimator is unchanged.
If u does not have a neighbor in S, then u is added to S. By calculation, if u is chosen randomly from the remaining vertices, the expected increase in the pessimistic estimator is non-negative. [The calculation: Conditioned on choosing a vertex in R(t), the probability that a given term 1 / (d(w) + 1) is dropped from the sum in the pessimistic estimator is at most (d(w) + 1) / | R(t) | , so the expected decrease in each term in the sum is at most 1 / | R(t) | . There are | R(t) | terms in the sum. Thus, the expected decrease in the sum is at most 1. Meanwhile, the size of S increases by 1.]
Thus, there must exist some choice of u that keeps the pessimistic estimator from decreasing.
Algorithm maximizing the pessimistic estimator
The algorithm below chooses each vertex u to maximize the resulting pessimistic estimator. By the previous considerations, this keeps the pessimistic estimator from decreasing and guarantees a successful outcome.
Below, N(t) denotes the neighbors of u in R(t) (that is, neighbors of u that are neither in S nor have a neighbor in S).
1. Initialize S to be the empty set. 2. While there exists a not-yet-considered vertex u with no neighbor in S: 3. Add such a vertex u to S where u minimizes
 .
4. Return S.
.
4. Return S.
Algorithms that don't maximize the pessimistic estimator
For the method of conditional probabilities to work, it suffices if the algorithm keeps the pessimistic estimator from decreasing (or increasing, as appropriate). The algorithm does not necessarily have to maximize (or minimize) the pessimistic estimator. This gives some flexibility in deriving the algorithm. The next two algorithms illustrate this.
1. Initialize S to be the empty set. 2. While there exists a vertex u in the graph with no neighbor in S: 3. Add such a vertex u to S, where u minimizes d(u) (the initial degree of u). 4. Return S.
1. Initialize S to be the empty set. 2. While the remaining graph is not empty: 3. Add a vertex u to S, where u has minimum degree in the remaining graph. 4. Delete u and all of u's neighbors from the graph. 5. Return S.
Each algorithm is analyzed with the same pessimistic estimator as before. With each step of either algorithm, the net increase in the pessimistic estimator is
where N(t)(u) denotes the neighbors of u in the remaining graph (that is, in R(t)).
For the first algorithm, the net increase is non-negative because, by the choice of u,
 ,
,
where d(u) is the degree of u in the original graph.
For the second algorithm, the net increase is non-negative because, by the choice of u,
 ,
,
where d'(u) is the degree of u in the remaining graph.
See also
- Probabilistic method
- Derandomization
References
- Erdös, Paul; Selfridge, J. L. (1973), "On a combinatorial game", Journal of Combinatorial Theory, Series A 14 (3): 298–301, doi:10.1016/0097-3165(73)90005-8.
- Spencer, Joel H. (1987), Ten lectures on the probabilistic method, SIAM, ISBN 9780898713251, http://books.google.com/books?id=Kz0B0KkwfVAC
- Raghavan, Prabhakar (1988), "Probabilistic construction of deterministic algorithms: approximating packing integer programs", Journal of Computer and System Sciences 37 (2): 130–143, doi:10.1016/0022-0000(88)90003-7.
Further reading
- Alon, Noga; Spencer, Joel (2008). The probabilistic method. Wiley-Interscience Series in Discrete Mathematics and Optimization (third ed.). Hoboken, NJ: John Wiley and Sons. pp. 250 et seq. (Second edition). ISBN 978-0-470-17020-5 , (Second 9780471370468). MR2437651. http://books.google.com/books?id=q3lUjheWiMoC&q=%22method+of+conditional+probabilities%22#v=snippet&q=%22method%20of%20conditional%20probabilities%22&f=false.
- Motwani, Rajeev; Raghavan, Prabhakar. Randomized algorithms. Cambridge University Press. pp. 120-. ISBN 9780521474658. http://books.google.com/books?id=QKVY4mDivBEC&q=%22method+of+conditional+probabilities%22#v=snippet&q=%22method%20of%20conditional%20probabilities%22&f=false.
- Vazirani, Vijay, Approximation algorithms, Springer Verlag, pp. 130-, ISBN 9783540653677, http://books.google.com/books?id=EILqAmzKgYIC&q=%22method+of+conditional%22#v=snippet&q=%22method%20of%20conditional%22&f=false
Categories:- Algorithms
- Probabilistic arguments




Wikimedia Foundation. 2010.