- Minimax estimator
-
In statistical decision theory, where we are faced with the problem of estimating a deterministic parameter (vector)
 from observations
from observations  an estimator (estimation rule)
an estimator (estimation rule)  is called minimax if its maximal risk is minimal among all estimators of
is called minimax if its maximal risk is minimal among all estimators of  . In a sense this means that is an estimator which performs best in the worst possible case allowed in the problem.
. In a sense this means that is an estimator which performs best in the worst possible case allowed in the problem.Contents
Problem setup
Consider the problem of estimating a deterministic (not Bayesian) parameter
from noisy or corrupt data  related through the conditional probability distribution
related through the conditional probability distribution  . Our goal is to find a "good" estimator
. Our goal is to find a "good" estimator  for estimating the parameter , which minimizes some given risk function
for estimating the parameter , which minimizes some given risk function  . Here the risk function is the expectation of some loss function
. Here the risk function is the expectation of some loss function  with respect to . A popular example for a loss function is the squared error loss
with respect to . A popular example for a loss function is the squared error loss  , and the risk function for this loss is the mean squared error (MSE).
, and the risk function for this loss is the mean squared error (MSE).Unfortunately in general the risk cannot be minimized, since it depends on the unknown parameter
itself (If we knew what was the actual value of , we wouldn't need to estimate it). Therefore additional criteria for finding an optimal estimator in some sense are required. One such criterion is the minimax criteria.Definition
Definition : An estimator
 is called minimax with respect to a risk function if it achieves the smallest maximum risk among all estimators, meaning it satisfies
is called minimax with respect to a risk function if it achieves the smallest maximum risk among all estimators, meaning it satisfiesLeast favorable distribution
Logically, an estimator is minimax when it is the best in the worst case. Continuing this logic, a minimax estimator should be a Bayes estimator with respect to a prior least favorable distribution of
. To demonstrate this notion denote the average risk of the Bayes estimator  with respect to a prior distribution
with respect to a prior distribution  as
asDefinition: A prior distribution
is called least favorable if for any other distribution  the average risk satisfies
the average risk satisfies  .
.Theorem 1: If
 then:
then:- is minimax.
- If is a unique Bayes estimator, it is also the unique minimax estimator.
- is least favorable.
Corollary: If a Bayes estimator has constant risk, it is minimax. Note that this is not a necessary condition.
Example 1, Unfair coin: Consider the problem of estimating the "success" rate of a Binomial variable,
 . This may be viewed as estimating the rate at which an unfair coin falls on "heads" or "tails". In this case the Bayes estimator with respect to a Beta-distributed prior,
. This may be viewed as estimating the rate at which an unfair coin falls on "heads" or "tails". In this case the Bayes estimator with respect to a Beta-distributed prior,  is
iswith constant Bayes risk
and, according to the Corollary, is minimax.
Definition: A sequence of prior distributions
 is called least favorable if for any other distribution ,
is called least favorable if for any other distribution ,Theorem 2: If there are a sequence of priors
 and an estimator
and an estimator  such that
such that  , then :
, then :- is minimax.
- The sequence is least favorable.
Notice that no uniqueness is guaranteed here. For example, the ML estimator from the previous example may be attained as the limit of Bayes estimators with respect to a uniform prior,
![\pi_n \sim U[-n,n]\,\!](3/8339dda023abd602b7860547949a0eee.png) with increasing support and also with respect to a zero mean normal prior
with increasing support and also with respect to a zero mean normal prior  with increasing variance. So neither the resulting ML estimator is unique minimax not the least favorable prior is unique.
with increasing variance. So neither the resulting ML estimator is unique minimax not the least favorable prior is unique.Example 2: Consider the problem of estimating the mean of
 dimensional Gaussian random vector,
dimensional Gaussian random vector,  . The Maximum likelihood (ML) estimator for in this case is simply
. The Maximum likelihood (ML) estimator for in this case is simply  , and it risk is
, and it risk is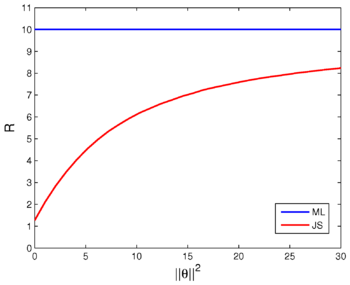 MSE of maximum likelihood estimator versus James–Stein estimator
MSE of maximum likelihood estimator versus James–Stein estimator
The risk is constant, but the ML estimator is actually not a Bayes estimator, so the Corollary of Theorem 1 does not apply. However, the ML estimator is the limit of the Bayes estimators with respect to the prior sequence
, and, hence, indeed minimax according to Theorem 2 . Nonetheless, minimaxity does not always imply admissibility. In fact in this example, the ML estimator is known to be inadmissible (not admissible) whenever  . The famous James–Stein estimator dominates the ML whenever . Though both estimators have the same risk
. The famous James–Stein estimator dominates the ML whenever . Though both estimators have the same risk  when
when  , and they are both minimax, the James–Stein estimator has smaller risk for any finite
, and they are both minimax, the James–Stein estimator has smaller risk for any finite  . This fact is illustrated in the following figure.
. This fact is illustrated in the following figure.Some examples
In general it is difficult, often even impossible to determine the minimax estimator. Nonetheless, in many cases a minimax estimator has been determined.
Example 3, Bounded Normal Mean: When estimating the Mean of a Normal Vector
 , where it is known that
, where it is known that  . The Bayes estimator with respect to a prior which is uniformly distributed on the edge of the bounding sphere is known to be minimax whenever
. The Bayes estimator with respect to a prior which is uniformly distributed on the edge of the bounding sphere is known to be minimax whenever  . The analytical expression for this estimator is
. The analytical expression for this estimator iswhere
 , is the modified Bessel function of the first kind of order n.
, is the modified Bessel function of the first kind of order n.Relationship to Robust Optimization
Robust optimization is an approach to solve optimization problems under uncertainty in the knowledge of underlying parameters,.[1][2] For instance, the MMSE Bayesian estimation of a parameter requires the knowledge of parameter correlation function. If the knowledge of this correlation function is not perfectly available, a popular minimax robust optimization approach[3] is to define a set characterizing the uncertainty about the correlation function, and then pursuing a minimax optimization over the uncertainty set and the estimator respectively. Similar minimax optimizations can be pursued to make estimators robust to certain imprecisely known parameters. For instance, a recent study dealing with such techniques in the area of signal processing can be found in [4].
In R. Fandom Noubiap and W. Seidel (2001) an algorithm for calculating a Gamma-minimax decision rule has been developed, when Gamma is given by a finite number of generalized moment conditions. Such a decision rule minimizes the maximum of the integrals of the risk function with respect to all distributions in Gamma. Gamma-minimax decision rules are of interest in robustness studies in Bayesian statistics.
References
- E. L. Lehmann and G. Casella (1998), Theory of Point Estimation, 2nd ed. New York: Springer-Verlag.
- F. Perron and E. Marchand (2002), "On the minimax estimator of a bounded normal mean," Statistics and Probability Letters 58: 327–333.
- J. O. Berger (1985), Statistical Decision Theory and Bayesian Analysis, 2nd ed. New York: Springer-Verlag. ISBN 0-387-96098-8.
- R. Fandom Noubiap and W. Seidel (2001), „An Algorithm for Calculating Gamma-Minimax Decision Rules under Generalized Moment Conditions“ ; Annals of Statistics, Aug., 2001, vol. 29, no. 4, p. 1094–1116
- Stein, C. (1981). "Estimation of the mean of a multivariate normal distribution". Annals of Statistics 9 (6): 1135–1151. doi:10.1214/aos/1176345632. MR630098. Zbl 0476.62035.
- ^ S. A. Kassam and H. V. Poor (1985), "Robust Techniques for Signal Processing: A Survey," Proceedings of the IEEE, vol. 73, pp. 433–481, March 1985.
- ^ A. Ben-Tal, L. El Ghoaoui, and A. Nemirovski (2009), "Robust Optimization", Princeton University Press, 2009.
- ^ S. Verdu and H. V. Poor (1984), "On Minimax Robustness: A general approach and applications," IEEE Transactions on Information Theory, vol. 30, pp. 328–340, March 1984.
- ^ M. Danish Nisar. "Minimax Robustness in Signal Processing for Communications", Shaker Verlag, ISBN 978-3-8440-0332-1, August 2011.
Categories:







Wikimedia Foundation. 2010.