- Kraft's inequality
-
In coding theory, Kraft's inequality, named after Leon Kraft, gives a necessary and sufficient condition for the existence of a uniquely decodable code for a given set of codeword lengths. Its applications to prefix codes and trees often find use in computer science and information theory.
More specifically, Kraft's inequality limits the lengths of codewords in a prefix code: if one takes an exponential function of each length, the resulting values must look like a probability mass function. Kraft's inequality can be thought of in terms of a constrained budget to be spent on codewords, with shorter codewords being more expensive.
- If Kraft's inequality holds with strict inequality, the code has some redundancy.
- If Kraft's inequality holds with strict equality, the code in question is a complete code.
- If Kraft's inequality does not hold, the code is not uniquely decodable.
Kraft's inequality was published by Kraft (1949). However, Kraft's paper discusses only prefix codes, and attributes the analysis leading to the inequality to Raymond Redheffer. The inequality is sometimes also called the Kraft–McMillan theorem after the independent discovery of the result by McMillan (1956); McMillan proves the result for the general case of uniquely decodable codes, and attributes the version for prefix codes to a spoken observation in 1955 by Joseph Leo Doob.
Contents
Examples
Binary trees
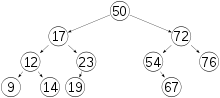 9, 14, 19, 67 and 76 are leaf nodes at depths of 3, 3, 3, 3 and 2, respectively.
9, 14, 19, 67 and 76 are leaf nodes at depths of 3, 3, 3, 3 and 2, respectively.
Any binary tree can be viewed as defining a prefix code for the leaves of the tree. Kraft's inequality states that
Here the sum is taken over the leaves of the tree, i.e. the nodes without any children. The depth is the distance to the root node. In the tree to the right, this sum is
Chaitin's constant
In algorithmic information theory, Chaitin's constant is defined as
This is an infinite sum which has one summand for every syntactically correct program which halts. |p| stands for the length of the bit string of p. The programs are required to be prefix-free in the sense that no summand has a prefix representing a syntactically valid program that halts. Hence the bit strings are prefix codes, and Kraft's inequality gives that
 .
.Formal statement
Let each source symbol from the alphabet
be encoded into a uniquely decodable code over an alphabet of size r with codeword lengths
Then
Conversely, for a given set of natural numbers
 satisfying the above inequality, there exists a uniquely decodable code over an alphabet of size r with those codeword lengths.
satisfying the above inequality, there exists a uniquely decodable code over an alphabet of size r with those codeword lengths.A commonly occurring special case of a uniquely decodable code is a prefix code. Kraft's inequality therefore also holds for any prefix code.
Proof for prefix codes
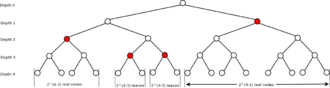 Example for binary tree. Red nodes represent a prefix tree leaf nodes. The method for calculation the number of descendant leaf nodes in the full tree is shown.
Example for binary tree. Red nodes represent a prefix tree leaf nodes. The method for calculation the number of descendant leaf nodes in the full tree is shown.Suppose that
 . Let A be the full r-ary tree of depth
. Let A be the full r-ary tree of depth  . Every word of length
. Every word of length  over an r-ary alphabet corresponds to a node in this tree at depth
over an r-ary alphabet corresponds to a node in this tree at depth  . The ith word in the prefix code corresponds to a node vi; let Ai be the set of all leaf nodes in the subtree of A rooted at vi. Clearly
. The ith word in the prefix code corresponds to a node vi; let Ai be the set of all leaf nodes in the subtree of A rooted at vi. ClearlySince the code is a prefix code,
 .
.
Thus, given that the total number of nodes at depth is  ,
,from which the result follows.
Conversely, given any ordered sequence of n natural numbers,
satisfying the Kraft's inequality, one can construct a prefix code with codeword lengths equal to
 by pruning subtrees from a full r-ary tree of depth . First choose any node from the full tree at depth
by pruning subtrees from a full r-ary tree of depth . First choose any node from the full tree at depth  and remove all of its descendents. This removes
and remove all of its descendents. This removes  fraction of the nodes from the full tree from being considered for the rest of the remaining codewords. Next iteration removes
fraction of the nodes from the full tree from being considered for the rest of the remaining codewords. Next iteration removes  fraction of the full tree for total of
fraction of the full tree for total of  . After m iterations,
. After m iterations,fraction of the full tree nodes are removed from consideration for any remaining codewords. But, by the assumption, this sum is less than 1 for all m < n, thus prefix code with lengths
can be constructed for all n source symbols.Proof of the general case
Consider the generating function in inverse of x for the code S
in which
 —the coefficient in front of
—the coefficient in front of  —is the number of distinct codewords of length . Here min is the length of the shortest codeword in S, and max is the length of the longest codeword in S.
—is the number of distinct codewords of length . Here min is the length of the shortest codeword in S, and max is the length of the longest codeword in S.For any positive integer m consider the m-fold product Sm, which consists of all the words of the form
 , where
, where  are indices between 1 and m. Note that, since S was assumed to uniquely decodable, if
are indices between 1 and m. Note that, since S was assumed to uniquely decodable, if  , then
, then  . In other words, every word in Sm comes from a unique sequence of codewords in S. Because of this property, one can compute the generating function G(x) for Sm from the generating function F(x) as
. In other words, every word in Sm comes from a unique sequence of codewords in S. Because of this property, one can compute the generating function G(x) for Sm from the generating function F(x) asHere, similarly as before,
 —the coefficient in front of in G(x)—is the number of words of length in Sm. Clearly, can not exceed
—the coefficient in front of in G(x)—is the number of words of length in Sm. Clearly, can not exceed  . Hence for any positive x
. Hence for any positive xSubstituting the value x = r we have
for any positive integer m. Left side of the inequality grows exponentially in m and right side only linearly. The only possibility for the inequality to be valid for all m is that
 . Looking back on the definition of F(x) we finally get the inequality.
. Looking back on the definition of F(x) we finally get the inequality.References
- Kraft, Leon G. (1949), A device for quantizing, grouping, and coding amplitude modulated pulses, Cambridge, MA: MS Thesis, Electrical Engineering Department, Massachusetts Institute of Technology, http://dspace.mit.edu/handle/1721.1/12390.
- McMillan, Brockway (1956), "Two inequalities implied by unique decipherability", IEEE Trans. Information Theory 2 (4): 115–116, doi:10.1109/TIT.1956.1056818, http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1056818.
External links
Categories:- Coding theory
- Inequalities
















Wikimedia Foundation. 2010.