- Levenberg–Marquardt algorithm
-
In mathematics and computing, the Levenberg–Marquardt algorithm (LMA)[1] provides a numerical solution to the problem of minimizing a function, generally nonlinear, over a space of parameters of the function. These minimization problems arise especially in least squares curve fitting and nonlinear programming.
The LMA interpolates between the Gauss–Newton algorithm (GNA) and the method of gradient descent. The LMA is more robust than the GNA, which means that in many cases it finds a solution even if it starts very far off the final minimum. For well-behaved functions and reasonable starting parameters, the LMA tends to be a bit slower than the GNA. LMA can also be viewed as Gauss–Newton using a trust region approach.
The LMA is a very popular curve-fitting algorithm used in many software applications for solving generic curve-fitting problems. However, the LMA finds only a local minimum, not a global minimum.
Contents
The problem
The primary application of the Levenberg–Marquardt algorithm is in the least squares curve fitting problem: given a set of m empirical datum pairs of independent and dependent variables, (xi, yi), optimize the parameters β of the model curve f(x,β) so that the sum of the squares of the deviations
becomes minimal.
The solution
Like other numeric minimization algorithms, the Levenberg–Marquardt algorithm is an iterative procedure. To start a minimization, the user has to provide an initial guess for the parameter vector, β. In cases with only one minimum, an uninformed standard guess like βT=(1,1,...,1) will work fine; in cases with multiple minima, the algorithm converges only if the initial guess is already somewhat close to the final solution.
In each iteration step, the parameter vector, β, is replaced by a new estimate, β + δ. To determine δ, the functions
 are approximated by their linearizations
are approximated by their linearizationswhere
is the gradient (row-vector in this case) of f with respect to β.
At its minimum, the sum of squares, S(β), the gradient of S with respect to δ will be zero. The above first-order approximation of
gives .
.
Or in vector notation,
 .
.
Taking the derivative with respect to δ and setting the result to zero gives:
where
 is the Jacobian matrix whose ith row equals Ji, and where
is the Jacobian matrix whose ith row equals Ji, and where  and
and  are vectors with ith component
are vectors with ith component  and yi, respectively. This is a set of linear equations which can be solved for δ.
and yi, respectively. This is a set of linear equations which can be solved for δ.Levenberg's contribution is to replace this equation by a "damped version",
where I is the identity matrix, giving as the increment, δ, to the estimated parameter vector, β.
The (non-negative) damping factor, λ, is adjusted at each iteration. If reduction of S is rapid, a smaller value can be used, bringing the algorithm closer to the Gauss–Newton algorithm, whereas if an iteration gives insufficient reduction in the residual, λ can be increased, giving a step closer to the gradient descent direction. Note that the gradient of S with respect to β equals
![-2(\mathbf{J}^{T} [\mathbf{y} - \mathbf{f}(\boldsymbol \beta) ] )^T](c/9bc98bc260f80c93c445e7c4e5843556.png) . Therefore, for large values of λ, the step will be taken approximately in the direction of the gradient. If either the length of the calculated step, δ, or the reduction of sum of squares from the latest parameter vector, β + δ, fall below predefined limits, iteration stops and the last parameter vector, β, is considered to be the solution.
. Therefore, for large values of λ, the step will be taken approximately in the direction of the gradient. If either the length of the calculated step, δ, or the reduction of sum of squares from the latest parameter vector, β + δ, fall below predefined limits, iteration stops and the last parameter vector, β, is considered to be the solution.Levenberg's algorithm has the disadvantage that if the value of damping factor, λ, is large, inverting JTJ + λI is not used at all. Marquardt provided the insight that we can scale each component of the gradient according to the curvature so that there is larger movement along the directions where the gradient is smaller. This avoids slow convergence in the direction of small gradient. Therefore, Marquardt replaced the identity matrix, I, with the diagonal matrix consisting of the diagonal elements of JTJ, resulting in the Levenberg–Marquardt algorithm:
![\mathbf{(J^T J + \lambda\, diag(J^T J))\boldsymbol \delta = J^T [y - f(\boldsymbol \beta)]}\!](3/163ce4ec9ad91a73c4f47854f3b886f4.png) .
.
A similar damping factor appears in Tikhonov regularization, which is used to solve linear ill-posed problems, as well as in ridge regression, an estimation technique in statistics.
Choice of damping parameter
Various more-or-less heuristic arguments have been put forward for the best choice for the damping parameter λ. Theoretical arguments exist showing why some of these choices guaranteed local convergence of the algorithm; however these choices can make the global convergence of the algorithm suffer from the undesirable properties of steepest-descent, in particular very slow convergence close to the optimum.
The absolute values of any choice depends on how well-scaled the initial problem is. Marquardt recommended starting with a value λ0 and a factor ν>1. Initially setting λ=λ0 and computing the residual sum of squares S(β) after one step from the starting point with the damping factor of λ=λ0 and secondly with λ0/ν. If both of these are worse than the initial point then the damping is increased by successive multiplication by ν until a better point is found with a new damping factor of λ0νk for some k.
If use of the damping factor λ/ν results in a reduction in squared residual then this is taken as the new value of λ (and the new optimum location is taken as that obtained with this damping factor) and the process continues; if using λ/ν resulted in a worse residual, but using λ resulted in a better residual then λ is left unchanged and the new optimum is taken as the value obtained with λ as damping factor.
Example
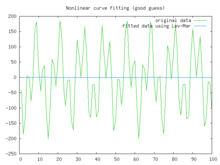 Poor fit
Poor fit
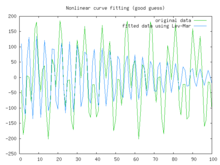 Better fit
Better fit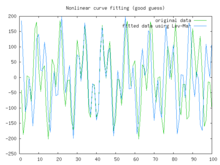 Best fit
Best fitIn this example we try to fit the function y = acos(bX) + bsin(aX) using the Levenberg–Marquardt algorithm implemented in GNU Octave as the leasqr function. The 3 graphs Fig 1,2,3 show progressively better fitting for the parameters a=100, b=102 used in the initial curve. Only when the parameters in Fig 3 are chosen closest to the original, are the curves fitting exactly. This equation is an example of very sensitive initial conditions for the Levenberg–Marquardt algorithm. One reason for this sensitivity is the existence of multiple minima — the function cos(βx) has minima at parameter value
 and
and 
Notes
- ^ The algorithm was first published by Kenneth Levenberg, while working at the Frankford Army Arsenal. It was rediscovered by Donald Marquardt who worked as a statistician at DuPont and independently by Girard, Wynn and Morrison.
See also
References
- Kenneth Levenberg (1944). "A Method for the Solution of Certain Non-Linear Problems in Least Squares". The Quarterly of Applied Mathematics 2: 164–168.
- A. Girard (1958). Rev. Opt 37: 225, 397.
- C.G. Wynne (1959). "Lens Designing by Electronic Digital Computer: I". Proc. Phys. Soc. London 73 (5): 777. doi:10.1088/0370-1328/73/5/310.
- Jorje J. Moré and Daniel C. Sorensen (1983). "Computing a Trust-Region Step". SIAM J. Sci. Stat. Comput. (4): 553–572.
- D.D. Morrison (1960). Jet Propulsion Laboratory Seminar proceedings.
- Donald Marquardt (1963). "An Algorithm for Least-Squares Estimation of Nonlinear Parameters". SIAM Journal on Applied Mathematics 11 (2): 431–441. doi:10.1137/0111030.
- Philip E. Gill and Walter Murray (1978). "Algorithms for the solution of the nonlinear least-squares problem". SIAM Journal on Numerical Analysis 15 (5): 977–992. doi:10.1137/0715063.
- Nocedal, Jorge; Wright, Stephen J. (2006). Numerical Optimization, 2nd Edition. Springer. ISBN 0-387-30303-0.
External links
Descriptions
- Detailed description of the algorithm can be found in Numerical Recipes in C, Chapter 15.5: Nonlinear models
- C. T. Kelley, Iterative Methods for Optimization, SIAM Frontiers in Applied Mathematics, no 18, 1999, ISBN 0-89871-433-8. Online copy
- History of the algorithm in SIAM news
- A tutorial by Ananth Ranganathan
- Methods for Non-Linear Least Squares Problems by K. Madsen, H.B. Nielsen, O. Tingleff is a tutorial discussing non-linear least-squares in general and the Levenberg-Marquardt method in particular
- T. Strutz: Data Fitting and Uncertainty (A practical introduction to weighted least squares and beyond). Vieweg+Teubner, ISBN 978-3-8348-1022-9.
Implementations
- Levenberg-Marquardt is a built-in algorithm with Mathematica
- Levenberg-Marquardt is a built-in algorithm with Matlab
- Levenberg-Marquardt is a built-in algorithm with Origin
- The oldest implementation still in use is lmdif, from MINPACK, in Fortran, in the public domain. See also:
- lmfit, a translation of lmdif into C/C++ with an easy-to-use wrapper for curve fitting, public domain.
- The GNU Scientific Library library has a C interface to MINPACK.
- C/C++ Minpack includes the Levenberg–Marquardt algorithm.
- Several high-level languages and mathematical packages have wrappers for the MINPACK routines, among them:
- Python library scipy, module
scipy.optimize.leastsq, - IDL, add-on MPFIT.
- R (programming language) has the minpack.lm package.
- Python library scipy, module
- levmar is an implementation in C/C++ with support for constraints, distributed under the GNU General Public License.
- levmar includes a MEX file interface for MATLAB
- Perl (PDL), python and Haskell interfaces to levmar are available: see PDL::Fit::Levmar, PyLevmar and HackageDB levmar.
- sparseLM is a C implementation aimed at minimizing functions with large, arbitrarily sparse Jacobians. Includes a MATLAB MEX interface.
- InMin library contains a C++ implementation of the algorithm based on the eigen C++ linear algebra library. It has a pure C-language API as well as a Python binding
- ALGLIB has implementations of improved LMA in C# / C++ / Delphi / Visual Basic. Improved algorithm takes less time to converge and can use either Jacobian or exact Hessian.
- NMath has an implementation for the .NET Framework.
- gnuplot uses its own implementation gnuplot.info.
- Java programming language implementations: 1) Javanumerics, 2) LMA-package (a small, user friendly and well documented implementation with examples and support), 3) Apache Commons Math
- OOoConv implements the L-M algorithm as an OpenOffice.org Calc spreadsheet.
- SAS, there are multiple ways to access SAS's implementation of the Levenberg-Marquardt algorithm: it can be accessed via NLPLM Call in PROC IML and it can also be accessed through the LSQ statement in PROC NLP, and the METHOD=MARQUARDT option in PROC NLIN.
Optimization: Algorithms, methods, and heuristics Unconstrained nonlinear: Methods calling ... ... and gradients... and Hessians
Constrained nonlinear GeneralDifferentiableAugmented Lagrangian methods · Sequential quadratic programming · Successive linear programmingConvex minimization GeneralBasis-exchangeCombinatorial ParadigmsApproximation algorithm · Dynamic programming · Greedy algorithm · Integer programming (Branch & bound or cut)Graph algorithmsMetaheuristics Categories:- Statistical algorithms
- Optimization methods
- Least squares
![S(\boldsymbol \beta) = \sum_{i=1}^m [y_i - f(x_i, \ \boldsymbol \beta) ]^2](9/8b99c8ceeacdf6449297a37e79bd542c.png)


![\mathbf{(J^{T}J)\boldsymbol \delta = J^{T} [y - f(\boldsymbol \beta)]} \!](2/842d772c5a91b761e19977ce05c5750b.png)
![\mathbf{(J^{T}J + \lambda I)\boldsymbol \delta = J^{T} [y - f(\boldsymbol \beta)]}\!](f/55f3b2ec29fd3ea2373a51584e139f31.png)



Wikimedia Foundation. 2010.