- Commitment ordering
-
In concurrency control of databases, transaction processing (transaction management), and related applications, Commitment ordering (or Commit ordering; CO; (Raz 1990, 1992, 1994, 2009)) is a class of interoperable Serializability techniques, both centralized and distributed. It allows optimistic (non-blocking) implementations. With the proliferation of Multi-core processors, CO has been also increasingly utilized in Concurrent programming, Transactional memory, and especially in Software transactional memory (STM) for achieving serializability optimistically. CO is also the name of the resulting transaction schedule (history) property, which was defined earlier (1988; CO was discovered independently) with the name Dynamic atomicity.[1] In a CO compliant schedule the chronological order of commitment events of transactions is compatible with the precedence order of the respective transactions. CO is a broad special case of Conflict serializability, and effective means (reliable, high-performance, distributed, and scalable) to achieve Global serializability (modular serializability) across any collection of database systems that possibly use different concurrency control mechanisms (CO also makes each system serializability compliant, if not already).
Each not-CO-compliant database system is augmented with a CO component (the Commitment Order Coordinator - COCO) which orders the commitment events for CO compliance, with neither data-access nor any other transaction operation interference. As such CO provides a low overhead, general solution for global serializability (and distributed serializability), instrumental for Global concurrency control (and Distributed concurrency control) of multi database systems and other transactional objects, possibly highly distributed (e.g., within Cloud computing, Grid computing, and networks of smartphones). An Atomic commitment protocol (ACP; of any type) is a fundamental part of the solution, utilized to break global cycles in the conflict (precedence, serializability) graph. CO is the most general property (a necessary condition) that guarantees global serializability, if the database systems involved do not share concurrency control information beyond atomic commitment protocol (unmodified) messages, and have no knowledge whether transactions are global or local (the database systems are autonomous). Thus CO (with its variants) is the only general technique that does not require the typically costly distribution of local concurrency control information (e.g., local precedence relations, locks, timestamps, or tickets). It generalizes the popular Strong strict two-phase locking (SS2PL) property, which in conjunction with the Two-phase commit protocol (2PC) is the de facto standard to achieve global serializability across (SS2PL based) database systems. As a result CO compliant database systems (with any, different concurrency control types) can transparently join such SS2PL based solutions for global serializability.
In addition, locking based global deadlocks are resolved automatically in a CO based multi-database environment, an important side-benefit (including the special case of a completely SS2PL based environment; a previously unnoticed fact for SS2PL).
Furthermore, Strict commitment ordering (SCO; Raz 1991c), the intersection of Strictness and CO, provides better performance (shorter average transaction completion time and resulting better transaction throughput) than SS2PL whenever read-write conflicts are present (identical blocking behavior for write-read and write-write conflicts; comparable locking overhead). The advantage of SCO is especially significant during lock contention. Strictness allows both SS2PL and SCO to use the same effective database recovery mechanisms.
Two major generalizing variants of CO exist, Extended CO (ECO; Raz 1993a) and Multi-version CO (MVCO; Raz 1993b). They as well provide global serializability without local concurrency control information distribution, can be combined with any relevant concurrency control, and allow optimistic (non-blocking) implementations. Both use additional information for relaxing CO constraints and achieving better concurrency and performance. Vote ordering (VO or Generalized CO (GCO); Raz 2009) is a container schedule set (property) and technique for CO and all its variants. Local VO is a necessary condition for guaranteeing Global serializability, if the atomic commitment protocol (ACP) participants do not share concurrency control information (have the Generalized autonomy property). CO and its variants inter-operate transparently, guaranteeing global serializability and automatic global deadlock resolution also together in a mixed, heterogeneous environment with different variants.
Overview
The Commitment ordering (CO; Raz 1990, 1992, 1994, 2009) schedule property has been referred to also as Dynamic atomicity (since 1988[1]), commit ordering, commit order serializability, and strong recoverability (since 1991). The latter is a misleading name since CO is incomparable with recoverability, and the term "strong" implies a special case. This means that a schedule with a strong recoverability property does not necessarily have the CO property, and vice versa.
In 2009 CO has been characterized as a major concurrency control method, together with the previously known (since the 1980s) three major methods: Locking, Time-stamp ordering, and Serialization graph testing, and as an enabler for the interoperability of systems using different concurrency control mechanisms.[2]
In a federated database system or any other more loosely defined multidatabase system, which are typically distributed in a communication network, transactions span multiple (and possibly Distributed databases. Enforcing global serializability in such system is problematic. Even if every local schedule of a single database is serializable, still, the global schedule of a whole system is not necessarily serializable. The massive communication exchanges of conflict information needed between databases to reach conflict serializability would lead to unacceptable performance, primarily due to computer and communication latency. The problem of achieving global serializability effectively had been characterized as open until the end of 1991.
Enforcing CO is an effective way to enforce conflict serializability globally in a distributed system, since enforcing CO locally in each database (or other transactional object) also enforces it globally. Each database may use any, possibly different, type of concurrency control mechanism. With a local mechanism that already provides conflict serializability, enforcing CO locally does not cause any additional aborts, since enforcing CO locally does not affect the data access scheduling strategy of the mechanism (this scheduling determines the serializability related aborts; such a mechanism typically does not consider the commitment events or their order). The CO solution requires no communication overhead, since it uses (unmodified) atomic commitment protocol messages only, already needed by each distributed transaction to reach atomicity. An atomic commitment protocol plays a central role in the distributed CO algorithm, which enforces CO globally, by breaking global cycles (cycles that span two or more databases) in the global conflict graph. CO, its special cases, and its generalizations are interoperable, and achieve global serializability while transparently being utilized together in a single heterogeneous distributed environment comprising objects with possibly different concurrency control mechanisms. As such, Commitment ordering, including its special cases, and together with its generalizations (see CO variants below), provides a general, high performance, fully distributed solution (no central processing component or central data structure are needed) for guaranteeing global serializability in heterogeneous environments of multidatabase systems and other multiple transactional objects (objects with states accessed and modified only by transactions; e.g., in the framework of transactional processes, and within Cloud computing and Grid computing). The CO solution scales up with network size and the number of databases without any negative impact on performance (assuming the statistics of a single distributed transaction, e.g., the average number of databases involved with a single transaction, are unchanged).
With the proliferation of Multi-core processors, Optimistic CO (OCO) has been also increasingly utilized to achieve serializability in software transactional memory, and numerous STM articles and patents utilizing "commit order" have already been published (e.g., Zhang et al. 2006[3]).
The commitment ordering solution for global serializability
General characterization of CO
Commitment ordering (CO) is a special case of conflict serializability. CO can be enforced with non-blocking mechanisms (each transaction can complete its task without having its data-access blocked, which allows optimistic concurrency control; however, commitment could be blocked). In a CO schedule the commitment events' (partial) precedence order of the transactions corresponds to the precedence (partial) order of the respective transactions in the (directed) conflict graph (precedence graph, serializability graph), as induced by their conflicting access operations (usually read and write (insert/modify/delete) operations; CO also applies to higher level operations, where they are conflicting if noncommutative, as well as to conflicts between operations upon multi-version data).
- Definition - Commitment ordering
- Let T1,T2 be two committed transactions in a schedule, such that T2 is in a conflict with T1 (T1 precedes T2). The schedule has the Commitment ordering (CO) property, if for every two such transactions T1 commits before T2 commits.
The commitment decision events are generated by either a local commitment mechanism, or an atomic commitment protocol, if different processes need to reach consensus on whether to commit or abort. The protocol may be distributed or centralized. Transactions may be committed concurrently, if the commit partial order allows (if they do not have conflicting operations). If different conflicting operations induce different partial orders of same transactions, then the conflict graph has cycles, and the schedule will violate serializability when all the transactions on a cycle are committed. In this case no partial order for commitment events can be found. Thus, cycles in the conflict graph need to be broken by aborting transactions. However, any conflict serializable schedule can be made CO without aborting any transaction, by properly delaying commit events to comply with the transactions' precedence partial order.
CO enforcement by itself is not sufficient as a concurrency control mechanism, since CO lacks the recoverability property, which should be supported as well.
The distributed CO algorithm
A fully distributed Global commitment ordering enforcement algorithm exists, that uses local CO of each participating database, and needs only (unmodified) Atomic commitment protocol messages with no further communication. The distributed algorithm is the combination of local (to each database) CO algorithm processes, and an atomic commitment protocol (which can be fully distributed). Atomic commitment protocol is essential to enforce atomicity of each distributed transaction (to decide whether to commit or abort it; this procedure is always carried out for distributed transactions, independently of concurrency control and CO). A common example of an atomic commitment protocol is the two-phase commit protocol, which is resilient to many types of system failure. In a reliable environment, or when processes usually fail together (e.g., in the same integrated circuit), a simpler protocol for atomic commitment may be used (e.g., a simple handshake of distributed transaction's participating processes with some arbitrary but known special participant, the transaction's coordinator, i.e., a type of one-phase commit protocol). An atomic commitment protocol reaches consensus among participants on whether to commit or abort a distributed (global) transaction that spans these participants. An essential stage in each such protocol is the YES vote (either explicit, or implicit) by each participant, which means an obligation of the voting participant to obey the decision of the protocol, either commit or abort. Otherwise a participant can unilaterally abort the transaction by an explicit NO vote. The protocol commits the transaction only if YES votes have been received from all participants, and thus typically a missing YES vote of a participant is considered a NO vote by this participant. Otherwise the protocol aborts the transaction. The various atomic commit protocols only differ in their abilities to handle different computing environment failure situations, and the amounts of work and other computing resources needed in different situations.
The entire CO solution for global serializability is based on the fact that in case of a missing vote for a distributed transaction, the atomic commitment protocol eventually aborts this transaction.
Enforcing global CO
In each database system a local CO algorithm determines the needed commitment order for that database. By the characterization of CO above, this order depends on the local precedence order of transactions, which results from the local data access scheduling mechanisms. Accordingly YES votes in the atomic commitment protocol are scheduled for each (unaborted) distributed transaction (in what follows "a vote" means a YES vote). If a precedence relation (conflict) exists between two transactions, then the second will not be voted on before the first is completed (either committed or aborted), to prevent possible commit order violation by the atomic commitment protocol. Such can happen since the commit order by the protocol is not necessarily the same as the voting order. If no precedence relation exists, both can be voted on concurrently. This vote ordering strategy ensures that also the atomic commitment protocol maintains commitment order, and it is a necessary condition for guaranteeing Global CO (and the local CO of a database; without it both Global CO and Local CO (a property meaning that each database is CO compliant) may be violated).
However, since database systems schedule their transactions independently, it is possible that the transactions' precedence orders in two databases or more are not compatible (no global partial order exists that can embed the respective local partial orders together). With CO precedence orders are also the commitment orders. When participating databases in a same distributed transaction do not have compatible local precedence orders for that transaction (without "knowing" it; typically no coordination between database systems exists on conflicts, since the needed communication is massive and unacceptably degrades performance) it means that the transaction resides on a global cycle (involving two or more databases) in the global conflict graph. In this case the atomic commitment protocol will fail to collect all the votes needed to commit that transaction: By the vote ordering strategy above at least one database will delay its vote for that transaction indefinitely, to comply with its own commitment (precedence) order, since it will be waiting to the completion of another, preceding transaction on that global cycle, delayed indefinitely by another database with a different order. This means a voting-deadlock situation involving the databases on that cycle. As a result the protocol will eventually abort some deadlocked transaction on this global cycle, since each such transaction is missing at least one participant's vote. Selection of the specific transaction on the cycle to be aborted depends on the atomic commitment protocol's abort policies (a timeout mechanism is common, but it may result in more than one needed abort per cycle; both preventing unnecessary aborts and abort time shortening can be achieved by a dedicated abort mechanism for CO). Such abort will break the global cycle involving that distributed transaction. Both deadlocked transactions and possibly other in conflict with the deadlocked (and thus blocked) will be free to be voted on. It is worthwhile noting that each database involved with the voting-deadlock continues to vote regularly on transactions that are not in conflict with its deadlocked transaction, typically almost all the outstanding transactions. Thus, in case of incompatible local (partial) commitment orders, no action is needed since the atomic commitment protocol resolves it automatically by aborting a transaction that is a cause of incompatibility. This means that the above vote ordering strategy is also a sufficient condition for guaranteeing Global CO.
The following is concluded:
- The Vote ordering strategy for Global CO Enforcing Theorem
- Let T1,T2 be undecided (neither committed nor aborted) transactions in a database system that enforces CO for local transactions, such that T2 is global and in conflict with T1 (T1 precedes T2). Then, having T1 ended (either committed or aborted) before T2 is voted on to be committed (the vote ordering strategy), in each such database system in a multidatabase environment, is a necessary and sufficient condition for guaranteeing Global CO (the condition guarantees Global CO, which may be violated without it).
- Comments:
- The vote ordering strategy that enforces global CO is referred to as CD3C in (Raz 1992).
- The Local CO property of a global schedule means that each database is CO compliant. From the necessity discussion part above it directly follows that the theorem is true also when replacing "Global CO" with "Local CO" when global transactions are present. Together it means that Global CO is guaranteed if and only if Local CO is guaranteed (which is untrue for Global conflict serializability and Local conflict serializability: Global implies Local, but not the opposite).
Global CO implies Global serializability.
The Global CO algorithm comprises enforcing (local) CO in each participating database system by ordering commits of local transactions (see Enforcing CO locally below) and enforcing the vote ordering strategy in the theorem above (for global transactions).
Exact characterization of voting-deadlocks by global cycles
The above global cycle elimination process by a voting deadlock can be explained in detail by the following observation:
First it is assumed, for simplicity, that every transaction reaches the ready-to-commit state and is voted on by at least one database (this implies that no blocking by locks occurs). Define a "wait for vote to commit" graph as a directed graph with transactions as nodes, and a directed edge from any first transaction to a second transaction if the first transaction blocks the vote to commit of the second transaction (opposite to conventional edge direction in a wait-for graph). Such blocking happens only if the second transaction is in a conflict with the first transaction (see above). Thus this "wait for vote to commit" graph is identical to the global conflict graph. A cycle in the "wait for vote to commit" graph means a deadlock in voting. Hence there is a deadlock in voting if and only if there is a cycle in the conflict graph. Local cycles (confined to a single database) are eliminated by the local serializability mechanisms. Consequently only global cycles are left, which are then eliminated by the atomic commitment protocol when it aborts deadlocked transactions with missing (blocked) respective votes.
Secondly, also local commits are dealt with: Note that when enforcing CO also waiting for a regular local commit of a local transaction can block local commits and votes of other transactions upon conflicts, and the situation for global transactions does not change also without the simplifying assumption above: The final result is the same also with local commitment for local transactions, without voting in atomic commitment for them.
Finally, blocking by a lock (which has been excluded so far) needs to be considered: A lock blocks a conflicting operation and prevents a conflict from being materialized. If the lock is released only after transaction end, it may block indirectly either a vote or a local commit of another transaction (which now cannot get to ready state), with the same effect as of a direct blocking of a vote or a local commit. In this case a cycle is generated in the conflict graph only if such a blocking by a lock is also represented by an edge. With such added edges representing events of blocking-by-a-lock, the conflict graph is becoming an augmented conflict graph.
- Definition - Augmented conflict graph
- An augmented conflict graph is a conflict graph with added edges: In addition to the original edges a directed edge exists from transaction T1 to transaction T2 if two conditions are met:
- T2 is blocked by a data-access lock applied by T1 (the blocking prevents the conflict of T2 with T1 from being materialized and have an edge in the regular conflict graph), and
- This blocking will not stop before T1 ends (commits or aborts; true for any locking-based CO)
- The graph can also be defined as the union of the (regular) conflict graph with the (reversed edge, regular) wait-for graph
- Comments:
- Here, unlike the regular conflict graph, which has edges only for materialized conflicts, all conflicts, both materialized and non-materialized, are represented by edges.
- Note that all the new edges are all the (reversed to the conventional) edges of the wait-for graph. The wait-for graph can be defined also as the graph of non-materialized conflicts. By the common conventions edge direction in a conflict graph defines time order between conflicting operations which is opposite to the time order defined by an edge in a wait-for graph.
- Note that such global graph contains (has embedded) all the (reversed edge) regular local wait-for graphs, and also may include locking based global cycles (which cannot exist in the local graphs). For example, if all the databases on a global cycle are SS2PL based, then all the related vote blocking situations are caused by locks (this is the classical, and probably the only global deadlock situation dealt with in the database research literature). This is a global deadlock case where each related database creates a portion of the cycle, but the complete cycle does not reside in any local wait-for graph.
In the presence of CO the augmented conflict graph is in fact a (reversed edge) local-commit and voting wait-for graph: An edge exists from a first transaction, either local or global, to a second, if the second is waiting for the first to end in order to be either voted on (if global), or locally committed (if local). All global cycles (across two or more databases) in this graph generate voting-deadlocks. The graph's global cycles provide complete characterization for voting deadlocks and may include any combination of materialized and non-materialized conflicts. Only cycles of (only) materialized conflicts are also cycles of the regular conflict graph and affect serializability. One or more (lock related) non-materialized conflicts on a cycle prevent it from being a cycle in the regular conflict graph, and make it a locking related deadlock. All the global cycles (voting-deadlocks) need to be broken (resolved) to both maintain global serializability and resolve global deadlocks involving data access locking, and indeed they are all broken by the atomic commitment protocol due to missing votes upon a voting deadlock.
Comment: This observation also explains the correctness of Extended CO (ECO) below: Global transactions' voting order must follow the conflict graph order with vote blocking when order relation (graph path) exists between two global transactions. Local transactions are not voted on, and their (local) commits are not blocked upon conflicts. This results in same voting-deadlock situations and resulting global cycle elimination process for ECO.
The voting-deadlock situation can be summarized as follows:
- The CO Voting-Deadlock Theorem
- Let a multidatabase environment comprise CO compliant (which eliminates local cycles) database systems that enforce, each, Global CO (using the condition in the theorem above). Then a voting-deadlock occurs if and only if a global cycle (spans two or more databases) exists in the Global augmented conflict graph (also blocking by a data-access lock is represented by an edge). If the cycle does not break by any abort, then all the global transactions on it are involved with the respective voting-deadlock, and eventually each has its vote blocked (either directly, or indirectly by a data-access lock); if a local transaction resides on the cycle, eventually it has its (local) commit blocked.
- Comment: A rare situation of a voting deadlock (by missing blocked votes) can happen, with no voting for any transaction on the related cycle by any of the database systems involved with these transactions. This can occur when local sub-transactions are multi-threaded. The highest probability instance of such rare event involves two transactions on two simultaneous opposite cycles. Such global cycles (deadlocks) overlap with local cycles which are resolved locally, and thus typically resolved by local mechanisms without involving atomic commitment. Formally it is also a global cycle, but practically it is local (portions of local cycles generate a global one; to see this, split each global transaction (node) to local sub-transactions (its portions confined each to a single database); a directed edge exists between transactions if an edge exists between any respective local sub-transactions; a cycle is local if all its edges originate from a cycle among sub-transactions of the same database, and global if not; global and local can overlap: a same cycle among transactions can result from several different cycles among sub-transactions, and be both local and global).
Also the following locking based special case is concluded:
- The CO Locking-based Global-Deadlock Theorem
- In a CO compliant multidatabase system a locking-based global-deadlock, involving at least one data-access lock (non-materialized conflict), and two or more database systems, is a reflection of a global cycle in the Global augmented conflict graph, which results in a voting-deadlock. Such cycle is not a cycle in the (regular) Global conflict graph (which reflects only materialized conflicts, and thus such cycle does not affect serializability).
- Comments:
- Any blocking (edge) in the cycle that is not by a data-access lock is a direct blocking of either voting or local commit. All voting-deadlocks are resolved (almost all by Atomic commitment; see comment above), including this locking-based type.
- Locking-based global-deadlocks can be generated also in a completely SS2PL-based distributed environment (special case of CO based), where all the vote blocking (and voting-deadlocks) are caused by data-access locks. Many research articles have dealt for years with resolving such global deadlocks, but none (except the CO articles) is known (as of 2009) to notice that atomic commitment automatically resolves them. Such automatic resolutions are regularly occurring unnoticed in all existing SS2PL based multidatabase systems, often bypassing dedicated resolution mechanisms.
Voting-deadlocks are the key for the operation of distributed CO.
Global cycle elimination (here voting-deadlock resolution by atomic commitment) and resulting aborted transactions' re-executions are time consuming, regardless of concurrency control used. If databases schedule transactions independently, global cycles are unavoidable (in a complete analogy to cycles/deadlocks generated in local SS2PL; with distribution, any transaction or operation scheduling coordination results in autonomy violation, and typically also in substantial performance penalty). However, in many cases their likelihood can be made very low by implementing database and transaction design guidelines that reduce the number of conflicts involving a global transaction. This, primarily by properly handling hot spots (database objects with frequent access), and avoiding conflicts by using commutativity when possible (e.g., when extensively using counters, as in finances, and especially multi-transaction accumulation counters, which are typically hot spots).
Atomic commitment protocols are intended and designed to achieve atomicity without considering database concurrency control. They abort upon detecting or heuristically finding (e.g., by timeout; sometimes mistakenly, unnecessarily) missing votes, and typically unaware of global cycles. These protocols can be specially enhanced for CO (including CO's variants below) both to prevent unnecessary aborts, and to accelerate aborts used for breaking global cycles in the global augmented conflict graph (for better performance by earlier release upon transaction-end of computing resources and typically locked data). For example, existing locking based global deadlock detection methods, other than timeout, can be generalized to consider also local commit and vote direct blocking, besides data access blocking. A possible compromise in such mechanisms is effectively detecting and breaking the most frequent and relatively simple to handle length-2 global cycles, and using timeout for undetected, much less frequent, longer cycles.
Enforcing CO locally
Commitment ordering can be enforced locally (in a single database) by a dedicated CO algorithm, or by any algorithm/protocol that provides any special case of CO. An important such protocol, being utilized extensively in database systems, which generates a CO schedule, is the strong strict two phase locking protocol (SS2PL: "release transaction's locks only after the transaction has been either committed or aborted"; see below). SS2PL is a proper subset of the intersection of 2PL and strictness.
A generic local CO algorithm
A generic local CO algorithm (Raz 1992; Algorithm 4.1) is an algorithm independent of implementation details, that enforces exactly the CO property. It does not block data access (nonblocking), and consists of aborting a certain set of transactions (only if needed) upon committing a transaction. It aborts a (uniquely determined at any given time) minimal set of other undecided (neither committed, nor aborted) transactions that run locally and can cause serializability violation in the future (can later generate cycles of committed transactions in the conflict graph; this is the ABORT set of a committed transaction T; after committing T no transaction in ABORT at commit time can be committed, and all of them are doomed to be aborted). This set consists of all undecided transactions with directed edges in the conflict graph to the committed transaction. The size of this set cannot increase when that transaction is waiting to be committed (in ready state: processing has ended), and typically decreases in time as its transactions are being decided. Thus, unless real-time constraints exist to complete that transaction, it is preferred to wait with committing that transaction and let this set decrease in size. If another serializability mechanism exists locally (which eliminates cycles in the local conflict graph), or if no cycle involving that transaction exists, the set will be empty eventually, and no abort of set member is needed. Otherwise the set will stabilize with transactions on local cycles, and aborting set members will have to occur to break the cycles. Since in the case of CO conflicts generate blocking on commit, local cycles in the augments conflict graph (see above) indicate local commit-deadlocks, and deadlock resolution techniques as in SS2PL can be used (e.g., like timeout and wait-for graph). A local cycle in the augmented conflict graph with at least one non-materialized conflict reflects a locking-based deadlock. The local algorithm above, applied to the local augmented conflict graph rather than the regular local conflict graph, comprises the generic enhanced local CO algorithm, a single local cycle elimination mechanism, for both guaranteeing local serializability and handling locking based local deadlocks. Practically an additional concurrency control mechanism is always utilized, even solely to enforce recoverability. The generic CO algorithm does not affect local data access scheduling strategy, when it runs alongside of any other local concurrency control mechanism. It affects only the commit order, and for this reason it does not need to abort more transactions than those needed to be aborted for serializability violation prevention by any combined local concurrency control mechanism. The net effect of CO may be, at most, a delay of commit events (or voting in a distributed environment), to comply with the needed commit order (but not more delay than its special cases, for example, SS2PL, and on the average significantly less).
The following theorem is concluded:
- The Generic Local CO Algorithm Theorem
- When running alone or alongside any concurrency control mechanism in a database system then
- The Generic local CO algorithm guarantees (local) CO (a CO compliant schedule).
- The Generic enhanced local CO algorithm guarantees both (local) CO and (local) locking based deadlock resolution.
- and (when not using timeout, and no real-time transaction completion constraints are applied) neither algorithm aborts more transactions than the minimum needed (which is determined by the transactions' operations scheduling, out of the scope of the algorithms).
Example: Concurrent programming and Transactional memory
- See also Concurrent programming and Transactional memory
With the proliferation of Multi-core processors, variants of the Generic local CO algorithm have been also increasingly utilized in Concurrent programming, Transactional memory, and especially in Software transactional memory for achieving serializability optimistically by "commit order" (e.g., Ramadan et al. 2009,[4] Zhang et al. 2006,[3] von Parun et al. 2007[5]). Numerous related articles and patents utilizing CO have already been published.
Implementation considerations - The Commitment Order Coordinator (COCO)
A database system in a multidatabase environment is assumed. From a software architecture point of view a CO component that implements the generic CO algorithm locally, the Commitment Order Coordinator (COCO), can be designed in a straightforward way as a mediator between a (single) database system and an atomic commitment protocol component (Raz 1991b). However, the COCO is typically an integral part of the database system. The COCO's functions are to vote to commit on ready global transactions (processing has ended) according to the local commitment order, to vote to abort on transactions for which the database system has initiated an abort (the database system can initiate abort for any transaction, for many reasons), and to pass the atomic commitment decision to the database system. For local transactions (when can be identified) no voting is needed. For determining the commitment order the COCO maintains an updated representation of the local conflict graph (or local augmented conflict graph for capturing also locking deadlocks) of the undecided (neither committed nor aborted) transactions as a data structure (e.g., utilizing mechanisms similar to locking for capturing conflicts, but with no data-access blocking). The COCO component has an interface with its database system to receive "conflict," "ready" (processing has ended; readiness to vote on a global transaction or commit a local one), and "abort" notifications from the database system. It also interfaces with the atomic commitment protocol to vote and to receive the atomic commitment protocol's decision on each global transaction. The decisions are delivered from the COCO to the database system through their interface, as well as local transactions' commit notifications, at a proper commit order. The COCO, including its interfaces, can be enhanced, if it implements another variant of CO (see below), or plays a role in the database's concurrency control mechanism beyond voting in atomic commitment.
The COCO also guarantees CO locally in a single, isolated database system with no interface with an atomic commitment protocol.
CO is a necessary condition for global serializability across autonomous database systems
If the databases that participate in distributed transactions (i.e., transactions that span more than a single database) do not use any shared concurrency control information and use unmodified atomic commitment protocol messages (for reaching atomicity), then maintaining (local) commitment ordering or one of its generalizing variants (see below) is a necessary condition for guaranteeing global serializability (a proof technique can be found in (Raz 1992), and a different proof method for this in (Raz 1993a)); it is also a sufficient condition. This is a mathematical fact derived from the definitions of serializability and a transaction. It means that if not complying with CO, then global serializability cannot be guaranteed under this condition (the condition of no local concurrency control information sharing between databases beyond atomic commit protocol messages). Atomic commitment is a minimal requirement for a distributed transaction since it is always needed, which is implied by the definition of transaction.
(Raz 1992) defines database autonomy and independence as complying with this requirement without using any additional local knowledge:
- Definition - (Concurrency control based) Autonomous Database System
- A database system is Autonomous, if it does not share with any other entity any concurrency control information beyond unmodified atomic commitment protocol messages. In addition it does not use for concurrency control any additional local information beyond conflicts (the last sentence does not appear explicitly but rather implied by further discussion in Raz 1992).
Using this definition the following is concluded:
- The CO and Global serializability Theorem
- CO compliance of every autonomous database system (or transactional object) in a multidatabase environment is a necessary condition for guaranteeing Global serializability (without CO Global serializability may be violated).
- CO compliance of every database system is a sufficient condition for guaranteeing Global serializability.
However, the definition of autonomy above implies, for example, that transactions are scheduled in a way that local transactions (confined to a single database) cannot be identified as such by an autonomous database system. This is realistic for some transactional objects, but too restrictive and less realistic for general purpose database systems. If autonomy is augmented with the ability to identify local transactions, then compliance with a more general property, Extended commitment ordering (ECO, see below), makes ECO the necessary condition.
Only in (Raz 2009) the notion of Generalized autonomy captures the intended notion of autonomy:
- Definition - Generalized autonomy
- A database system has the Generalized autonomy property, if it does not share with any other database system any local concurrency information beyond (unmodified) atomic commit protocol messages (however any local information can be utilized).
This definition is probably the broadest such definition possible in the context of database concurrency control, and it makes CO together with any of its (useful: No concurrency control information distribution) generalizing variants (Vote ordering (VO); see CO variants below) the necessary condition for Global serializability (i.e., the union of CO and its generalizing variants is the necessary set VO, which may include also new unknown useful generalizing variants).
Summary
The Commitment ordering (CO) solution (technique) for global serializability can be summarized as follows:
If each database (or any other transactional object) in a multidatabase environment complies with CO, i.e., arranges its local transactions' commitments and its votes on (global, distributed) transactions to the atomic commitment protocol according to the local (to the database) partial order induced by the local conflict graph (serializability graph) for the respective transactions, then Global CO and Global serializability are guaranteed. A database's CO compliance can be achieved effectively with any local conflict serializability based concurrency control mechanism, with neither affecting any transaction's execution process or scheduling, nor aborting it. Also the database's autonomy is not violated. The only low overhead incurred is detecting conflicts (e.g., as with locking, but with no data-access blocking; if not already detected for other purposes), and ordering votes and local transactions' commits according to the conflicts.
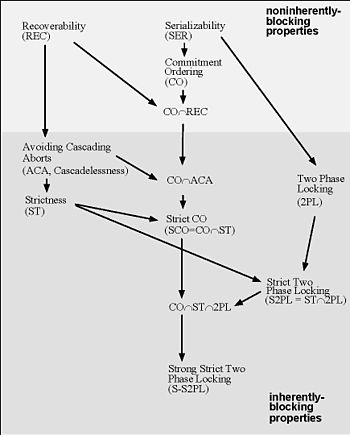 Schedule classes containment: An arrow from class A to class B indicates that class A strictly contains B; a lack of a directed path between classes means that the classes are incomparable. A property is inherently blocking, if it can be enforced only by blocking transaction’s data access operations until certain events occur in other transactions. (Raz 1992)
Schedule classes containment: An arrow from class A to class B indicates that class A strictly contains B; a lack of a directed path between classes means that the classes are incomparable. A property is inherently blocking, if it can be enforced only by blocking transaction’s data access operations until certain events occur in other transactions. (Raz 1992)
In case of incompatible partial orders of two or more databases (no global partial order can embed the respective local partial orders together), a global cycle (spans two databases or more) in the global conflict graph is generated. This, together with CO, results in a cycle of blocked votes, and a voting-deadlock occurs for the databases on that cycle (however, allowed concurrent voting in each database, typically for almost all the outstanding votes, continue to execute). In this case the atomic commitment protocol fails to collect all the votes needed for the blocked transactions on that global cycle, and consequently the protocol aborts some transaction with a missing vote. This breaks the global cycle, the voting-deadlock is resolved, and the related blocked votes are free to be executed. Breaking the global cycle in the global conflict graph ensures that both global CO and global serializability are maintained. Thus, in case of incompatible local (partial) commitment orders no action is needed since the atomic commitment protocol resolves it automatically by aborting a transaction that is a cause for the incompatibility. Furthermore, also global deadlocks due to locking (global cycles in the augmented conflict graph with at least one data access blocking) result in voting deadlocks and are resolved automatically by the same mechanism.
Local CO is a necessary condition for guaranteeing Global serializability, if the databases involved do not share any concurrency control information beyond (unmodified) atomic commitment protocol messages, i.e., if the databases are autonomous in the context of concurrency control. This means that every global serializability solution for autonomous databases must comply with CO. Otherwise global serializability may be violated (and thus, is likely to be violated very quickly in a high-performance environment).
The CO solution scales up with network size and the number of databases without performance penalty when it utilizes common distributed atomic commitment architecture.
Distributed serializability and CO
Distributed CO
A distinguishing characteristic of the CO solution to distributed serializability from other techniques is the fact that it requires no conflict information distributed (e.g., local precedence relations, locks, timestamps, tickets), which makes it uniquely effective. It utilizes (unmodified) atomic commitment protocol messages (which are already used) instead.
A common way to achieve distributed serializability in a (distributed) system is by a distributed lock manager (DLM). DLMs, which communicate lock (non-materialized conflict) information in a distributed environment, typically suffer from computer and communication latency, which reduces the performance of the system. CO allows to achieve distributed serializability under very general conditions, without a distributed lock manager, exhibiting the benefits already explored above for multidatabase environments; in particular: reliability, high performance, scalability, possibility of using optimistic concurrency control when desired, no conflict information related communications over the network (which have incurred overhead and delays), and automatic distributed deadlock resolution.
All distributed transactional systems rely on some atomic commitment protocol to coordinate atomicity (whether to commit or abort) among processes in a distributed transaction. Also, typically recoverable data (i.e., data under transactions' control, e.g., database data; not to be confused with the recoverability property of a schedule) are directly accessed by a single transactional data manager component (also referred to as a resource manager) that handles local sub-transactions (the distributed transaction's portion in a single location, e.g., network node), even if these data are accessed indirectly by other entities in the distributed system during a transaction (i.e., indirect access requires a direct access through a local sub-transaction). Thus recoverable data in a distributed transactional system are typically partitioned among transactional data managers. In such system these transactional data managers typically comprise the participants in the system's atomic commitment protocol. If each participant complies with CO (e.g., by using SS2PL, or COCOs, or a combination; see above), then the entire distributed system provides CO (by the theorems above; each participant can be considered a separate transactional object), and thus (distributed) serializability. Furthermore: When CO is utilized together with an atomic commitment protocol also distributed deadlocks (i.e., deadlocks that span two or more data managers) caused by data-access locking are resolved automatically. Thus the following corollary is concluded:
- The CO Based Distributed Serializability Theorem
- Let a distributed transactional system (e.g., a distributed database system) comprise transactional data managers (also called resource managers) that manage all the system's recoverable data. The data managers meet three conditions:
- Data partition: Recoverable data are partitioned among the data managers, i.e., each recoverable datum (data item) is controlled by a single data manager (e.g., as common in a Shared nothing architecture; even copies of a same datum under different data managers are physically distinct, replicated).
- Participants in atomic commitment protocol: These data managers are the participants in the system's atomic commitment protocol for coordinating distributed transactions' atomicity.
- CO compliance: Each such data manager is CO compliant (or some CO variant compliant; see below).
- Then
- The entire distributed system guarantees (distributed CO and) serializability, and
- Data-access based distributed deadlocks (deadlocks involving two or more data managers with at least one non-materialized conflict) are resolved automatically.
- Furthermore: The data managers being CO compliant is a necessary condition for (distributed) serializability in a system meeting conditions 1, 2 above, when the data managers are autonomous, i.e., do not share concurrency control information beyond unmodified messages of atomic commitment protocol.
This theorem also means that when SS2PL (or any other CO variant) is used locally in each transactional data manager, and each data manager has exclusive control of its data, no distributed lock manager (which is often utilized to enforce distributed SS2PL) is needed for distributed SS2PL and serializability. It is relevant to a wide range of distributed transactional applications, which can be easily designed to meet the theorem's conditions.
Distributed optimistic CO (DOCO)
For implementing Distributed Optimistic CO (DOCO) the generic local CO algorithm is utilized in all the atomic commitment protocol participants in the system with no data access blocking and thus with no local deadlocks. The previous theorem has the following corollary:
- The Distributed optimistic CO (DOCO) Theorem
- If DOCO is utilized, then:
- No local deadlocks occur, and
- Global (voting) deadlocks are resolved automatically (and all are serializability related (with non-blocking conflicts) rather than locking related (with blocking and possibly also non-blocking conflicts)).
- Thus, no deadlock handling is needed.
Examples
Distributed SS2PL
A distributed database system that utilizes SS2PL resides on two remote nodes, A and B. The database system has two transactional data managers (resource managers), one on each node, and the database data are partitioned between the two data managers in a way that each has an exclusive control of its own (local to the node) portion of data: Each handles its own data and locks without any knowledge on the other manager's. For each distributed transaction such data managers need to execute the available atomic commitment protocol.
Two distributed transactions, T1 and T2, are running concurrently, and both access data x and y. x is under the exclusive control of the data manager on A (B's manager cannot access x), and y under that on B.
- T1 reads x on A and writes y on B, i.e., T1 = R1A(x) W1B(y) when using notation common for concurrency control.
- T2 reads y on B and writes x on A, i.e., T2 = R2B(y) W2A(x)
The respective local sub-transactions on A and B (the portions of T1 and T2 on each of the nodes) are the following:
-
Local sub-transactions Transaction \ Node A B T1 T1A = R1A(x) T1B = W1B(y) T2 T2A = W2A(x) T2B = R2B(y)
The database system's schedule at a certain point in time is the following:
- R1A(x) R2B(y)
- (also R2B(y) R1A(x) is possible)
T1 holds a read-lock on x and T2 holds read-locks on y. Thus W1B(y) and W2A(x) are blocked by the lock compatibility rules of SS2PL and cannot be executed. This is a distributed deadlock situation, which is also a voting-deadlock (see below) with a distributed (global) cycle of length 2 (number of edges, conflicts; 2 is the most frequent length). The local sub-transactions are in the following states:
- T1A is ready (execution has ended) and voted (in atomic commitment)
- T1B is running and blocked (a non-materialized conflict situation; no vote on it can occur)
- T2B is ready and voted
- T2A is running and blocked (a non-materialized conflict; no vote).
Since the atomic commitment protocol cannot receive votes for blocked sub-transactions (a voting-deadlock), it will eventually abort some transaction with a missing vote(s) by timeout, either T1, or T2, (or both, if the timeouts fall very close). This will resolve the global deadlock. The remaining transaction will complete running, be voted on, and committed. An aborted transaction is immediately restarted and re-executed.
Comments:
- The data partition (x on A; y on B) is important since without it, for example, x can be accessed directly from B. If a transaction T3 is running on B concurrently with T1 and T2 and directly writes x, then, without a distributed lock manager the read-lock for x held by T1 on A is not visible on B and cannot block the write of T3 (or signal a materialized conflict for a non-blocking CO variant; see below). Thus serializability can be violated.
- Due to data partition, x cannot be accessed directly from B. However, functionality is not limited, and a transaction running on B still can issue a write or read request of x (not common). This request is communicated to the transaction's local sub-transaction on A (which is generated, if does not exist already) which issues this request to the local data manager on A.
Variations
In the scenario above both conflicts are non-materialized, and the global voting-deadlock is reflected as a cycle in the global wait-for graph (but not in the global conflict graph; see Exact characterization of voting-deadlocks by global cycles above). However the database system can utilize any CO variant with exactly the same conflicts and voting-deadlock situation, and same resolution. Conflicts can be either materialized or non-materialized, depending on CO variant used. For example, if SCO (below) is used by the distributed database system instead of SS2PL, then the two conflicts in the example are materialized, all local sub-transactions are in ready states, and vote blocking occurs in the two transactions, one on each node, because of the CO voting rule applied independently on both A and B: due to conflicts T2A = W2A(x) is not voted on before T1A = R1A(x) ends, and T1B = W1B(y) is not voted on before T2B = R2B(y) ends, which is a voting-deadlock. Now the conflict graph has the global cycle (all conflicts are materialized), and again it is resolved by the atomic commitment protocol, and distributed serializability is maintained. Unlikely for a distributed database system, but possible in principle (and occurs in a multi-database), A can employ SS2PL while B employs SCO. In this case the global cycle is neither in the wait-for graph nor in the serializability graph, but still in the augmented conflict graph (the union of the two). The various combinations are summarized in the following table:
Voting-deadlock situations Case Node
ANode
BPossible schedule Materialized
conflicts
on cycleNon-
materialized
conflictsT1A =
R1A(x)T1B =
W1B(y)T2A =
W2A(x)T2B =
R2B(y)1 SS2PL SS2PL R1A(x) R2B(y) 0 2 Ready
VotedRunning
(Blocked)Running
(Blocked)Ready
Voted2 SS2PL SCO R1A(x) R2B(y) W1B(y) 1 1 Ready
VotedReady
Vote blockedRunning
(Blocked)Ready
Voted3 SCO SS2PL R1A(x) R2B(y) W2A(x) 1 1 Ready
VotedRunning
(Blocked)Ready
Vote blockedReady
Voted4 SCO SCO R1A(x) R2B(y) W1B(y) W2A(x) 2 0 Ready
VotedReady
Vote blockedReady
Vote blockedReady
Voted- Comments:
- Conflicts and thus cycles in the augmented conflict graph are determined by the transactions and their initial scheduling only, independently of the concurrency control utilized. With any variant of CO, any global cycle (i.e., spans two databases or more) causes a voting deadlock. Different CO variants may differ on whether a certain conflict is materialized or non-materialized.
- Some limited operation order changes in the schedules above are possible, constrained by the orders inside the transactions, but such changes do not change the rest of the table.
- As noted above, only case 4 describes a cycle in the (regular) conflict graph which affects serializability. Cases 1-3 describe cycles of locking based global deadlocks (at least one lock blocking exists). All cycle types are equally resolved by the atomic commitment protocol. Case 1 is the common Distributed SS2PL, utilized since the 1980s. However, no research article, except the CO articles, is known to notice this automatic locking global deadlock resolution as of 2009. Such global deadlocks typically have been dealt with by dedicated mechanisms.
- Case 4 above is also an example for a typical voting-deadlock when Distributed optimistic CO (DOCO) is used (i.e., Case 4 is unchanged when Optimistic CO (OCO; see below) replaces SCO on both A and B): No data-access blocking occurs, and only materialized conflicts exist.
Hypothetical Multi Single-Threaded Core (MuSiC) environment
Comment: While the examples above describe real, recommended utilization of CO, this example is hypothetical, for demonstration only.
Certain experimental distributed memory-resident databases advocate multi single-threaded core (MuSiC) transactional environments. "Single-threaded" refers to transaction threads only, and to serial execution of transactions. The purpose is possible orders of magnitude gain in performance (e.g., H-Store[6] and VoltDB) relatively to conventional transaction execution in multiple threads on a same core. In what described below MuSiC is independent of the way the cores are distributed. They may reside in one integrated circuit (chip), or in many chips, possibly distributed geographically in many computers. In such an environment, if recoverable (transactional) data are partitioned among threads (cores), and it is implemented in the conventional way for distributed CO, as described in previous sections, then DOCO and Strictness exist automatically. However, downsides exist with this straightforward implementation of such environment, and its practicality as a general-purpose solution is questionable. On the other hand tremendous performance gain can be achieved in applications that can bypass these downsides in most situations.
Comment: The MuSiC straightforward implementation described here (which uses, for example, as usual in distributed CO, voting (and transaction thread) blocking in atomic commitment protocol when needed) is for demonstration only, and has no connection to the implementation in H-Store or any other project.
In a MuSiC environment local schedules are serial. Thus both local Optimistic CO (OCO; see below) and the Global CO enforcement vote ordering strategy condition for the atomic commitment protocol are met automatically. This results in both distributed CO compliance (and thus distributed serializability) and automatic global (voting) deadlock resolution.
Furthermore, also local Strictness follows automatically in a serial schedule. By Theorem 5.2 in (Raz 1992; page 307), when the CO vote ordering strategy is applied, also Global Strictness is guaranteed. Note that serial locally is the only mode that allows strictness and "optimistic" (no data access blocking) together.
The following is concluded:
- The MuSiC Theorem
- In MuSiC environments, if recoverable (transactional) data are partitioned among cores (threads), then both
- OCO (and implied Serializability; i.e., DOCO and Distributed serializability)
- Strictness (allowing effective recovery; 1 and 2 implying Strict CO - see SCO below) and
- (voting) deadlock resolution
- automatically exist globally with unbounded scalability in number of cores used.
- Comment: However, two major downsides, which need special handling, may exist:
- Local sub-transactions of a global transaction are blocked until commit, which makes the respective cores idle. This reduces core utilization substantially, even if scheduling of the local sub-transactions attempts to execute all of them in time proximity, almost together. It can be overcome by detaching execution from commit (with some atomic commitment protocol) for global transactions, at the cost of possible cascading aborts.
- increasing the number of cores for a given amount of recoverable data (database size) decreases the average amount of (partitioned) data per core. This may make some cores idle, while others very busy, depending on data utilization distribution. Also a local (to a core) transaction may become global (multi-core) to reach its needed data, with additional incurred overhead. Thus, as the number of cores increases, the amount and type of data assigned to each core should be balanced according to data usage, so a core is neither overwhelmed to become a bottleneck, nor becoming idle too frequently and underutilized in a busy system. Another consideration is putting in a same core partition all the data that are usually accessed by a same transaction (if possible), to maximize the number of local transactions (and minimize the number of global, distributed transactions). This may be achieved by occasional data re-partition among cores based on load balancing (data access balancing) and patterns of data usage by transactions. Another way to considerably mitigate this downside is by proper physical data replication among some core partitions in a way that read-only global transactions are possibly (depending on usage patterns) completely avoided, and replication changes are synchronized by a dedicated commit mechanism.
CO variants: Interesting special cases and generalizations
Special case schedule property classes (e.g., SS2PL and SCO below) are strictly contained in the CO class. The generalizing classes (ECO and MVCO) strictly contain the CO class (i.e., include also schedules that are not CO compliant). The generalizing variants also guarantee global serializability without distributing local concurrency control information (each database has the generalized autonomy property: it uses only local information), while relaxing CO constraints and utilizing additional (local) information for better concurrency and performance: ECO uses knowledge about transactions being local (i.e., confined to a single database), and MVCO uses availability of data versions values. Like CO, both generalizing variants are non-blocking, do not interfere with any transaction's operation scheduling, and can be seamlessly combined with any relevant concurrency control mechanism.
The term CO variant refers in general to CO, ECO, MVCO, or a combination of each of them with any relevant concurrency control mechanism or property (including Multi-version based ECO, MVECO). No other interesting generalizing variants (which guarantee global serializability with no local concurrency control information distribution) are known, but may be discovered.
Strong strict two phase locking (SS2PL)
Main article: Two-phase lockingStrong Strict Two Phase Locking (SS2PL; also referred to as Rigorousness or Rigorous scheduling) means that both read and write locks of a transaction are released only after the transaction has ended (either committed or aborted). The set of SS2PL schedules is a proper subset of the set of CO schedules. This property is widely utilized in database systems, and since it implies CO, databases that use it and participate in global transactions generate together a serializable global schedule (when using any atomic commitment protocol, which is needed for atomicity in a multi-database environment). No database modification or addition is needed in this case to participate in a CO distributed solution: The set of undecided transactions to be aborted before committing in the local generic CO algorithm above is empty because of the locks, and hence such an algorithm is unnecessary in this case. A transaction can be voted on by a database system immediately after entering a "ready" state, i.e., completing running its task locally. Its locks are released by the database system only after it is decided by the atomic commitment protocol, and thus the condition in the Global CO enforcing theorem above is kept automatically. Interestingly, if a local timeout mechanism is used by a database system to resolve (local) SS2PL deadlocks, then aborting blocked transactions breaks not only potential local cycles in the global conflict graph (real cycles in the augmented conflict graph), but also database system's potential global cycles as a side effect, if the atomic commitment protocol's abort mechanism is relatively slow. Such independent aborts by several entities typically may result in unnecessary aborts for more than one transaction per global cycle. The situation is different for a local wait-for graph based mechanisms: Such cannot identify global cycles, and the atomic commitment protocol will break the global cycle, if the resulting voting deadlock is not resolved earlier in another database.
Local SS2PL together with atomic commitment implying global serializability can also be deduced directly: All transactions, including distributed, obey the 2PL (SS2PL) rules. The atomic commitment protocol mechanism is not needed here for consensus on commit, but rather for the end of phase-two synchronization point. Probably for this reason, without considering the atomic commitment voting mechanism, automatic global deadlock resolution has not been noticed before CO.
Strict CO (SCO)
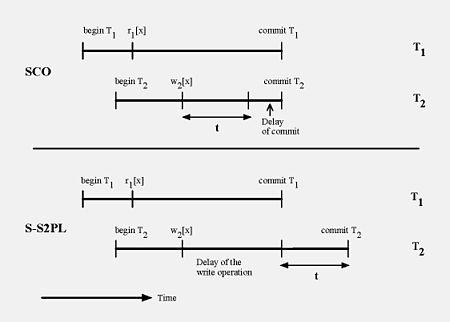 Read-write conflict: SCO Vs. SS2PL. Duration of transaction T2 is longer with SS2PL than with SCO. SS2PL delays write operation w2[x] of T2 until T1 commits, due to a lock on x by T1 following read operation r1[x]. If t time units are needed for transaction T2 after starting write operation w2[x] in order to reach ready state, than T2 commits t time units after T1 commits. However, SCO does not block w2[x], and T2 can commit immediately after T1 commits. (Raz 1991c)
Read-write conflict: SCO Vs. SS2PL. Duration of transaction T2 is longer with SS2PL than with SCO. SS2PL delays write operation w2[x] of T2 until T1 commits, due to a lock on x by T1 following read operation r1[x]. If t time units are needed for transaction T2 after starting write operation w2[x] in order to reach ready state, than T2 commits t time units after T1 commits. However, SCO does not block w2[x], and T2 can commit immediately after T1 commits. (Raz 1991c)Strict Commitment Ordering (SCO; (Raz 1991c)) is the intersection of strictness (a special case of recoverability) and CO, and provides an upper bound for a schedule's concurrency when both properties exist. It can be implemented using blocking mechanisms (locking) similar to those used for the popular SS2PL with similar overheads.
Unlike SS2PL, SCO does not block on a read-write conflict but possibly blocks on commit instead. SCO and SS2PL have identical blocking behavior for the other two conflict types: write-read, and write-write. As a result SCO has shorter average blocking periods, and more concurrency (e.g., performance simulations of a single database for the most significant variant of locks with ordered sharing, which is identical to SCO, clearly show this, with approximately 100% gain for some transaction loads; also for identical transaction loads SCO can reach higher transaction rates than SS2PL before lock thrashing occurs). More concurrency means that with given computing resources more transactions are completed in time unit (higher transaction rate, throughput), and the average duration of a transaction is shorter (faster completion; see chart). The advantage of SCO is especially significant during lock contention.
- The SCO Vs. SS2PL Performance Theorem
- SCO provides shorter average transaction completion time than SS2PL, if read-write conflicts exist. SCO and SS2PL are identical otherwise (have identical blocking behavior with write-read and write-write conflicts).
SCO is as practical as SS2PL since as SS2PL it provides besides serializability also strictness, which is widely utilized as a basis for efficient recovery of databases from failure. An SS2PL mechanism can be converted to an SCO one for better performance in a straightforward way without changing recovery methods. A description of a SCO implementation can be found in (Perrizo and Tatarinov 1998).[7] See also Semi-optimistic database scheduler.
SS2PL is a proper subset of SCO (which is another explanation why SCO is less constraining and provides more concurrency than SS2PL).
Optimistic CO (OCO)
For implementing Optimistic commitment ordering (OCO) the generic local CO algorithm is utilized without data access blocking, and thus without local deadlocks. OCO without transaction or operation scheduling constraints covers the entire CO class, and is not a special case of the CO class, but rather a useful CO variant and mechanism characterization.
Extended CO (ECO)
General characterization of ECO
Extended Commitment Ordering (ECO; (Raz 1993a)) generalizes CO. When local transactions (transactions confined to a single database) can be distinguished from global (distributed) transactions (transactions that span two databases or more), commitment order is applied to global transactions only. Thus, for a local (to a database) schedule to have the ECO property, the chronological (partial) order of commit events of global transactions only (unimportant for local transactions) is consistent with their order on the respective local conflict graph.
- Definition - Extended commitment ordering
- Let T1,T2 be two committed global transactions in a schedule, such that a directed path of unaborted transactions exists in the conflict graph (precedence graph) from T1 to T2 (T1 precedes T2, possibly transitively, indirectly). The schedule has the Extended commitment ordering (ECO) property, if for every two such transactions T1 commits before T2 commits.
A distributed algorithm to guarantee global ECO exists. As for CO, the algorithm needs only (unmodified) atomic commitment protocol messages. In order to guarantee global serializability, each database needs to guarantee also the conflict serializability of its own transactions by any (local) concurrency control mechanism.
- The ECO and Global Serializability Theorem
- (Local, which implies global) ECO together with local conflict serializability, is a sufficient condition to guarantee global conflict serializability.
- When no concurrency control information beyond atomic commitment messages is shared outside a database (autonomy), and local transactions can be identified, it is also a necessary condition.
- See a necessity proof in (Raz 1993a).
This condition (ECO with local serializability) is weaker than CO, and allows more concurrency at the cost of a little more complicated local algorithm (however, no practical overhead difference with CO exists).
When all the transactions are assumed to be global (e.g., if no information is available about transactions being local), ECO reduces to CO.
The ECO algorithm
Before a global transaction is committed, a generic local (to a database) ECO algorithm aborts a minimal set of undecided transactions (neither committed, nor aborted; either local transactions, or global that run locally), that can cause later a cycle in the conflict graph. This set of aborted transactions (not unique, contrary to CO) can be optimized, if each transaction is assigned with a weight (that can be determined by transaction's importance and by the computing resources already invested in the running transaction; optimization can be carried out, for example, by a reduction from the Max flow in networks problem (Raz 1993a)). Like for CO such a set is time dependent, and becomes empty eventually. Practically, almost in all needed implementations a transaction should be committed only when the set is empty (and no set optimization is applicable). The local (to the database) concurrency control mechanism (separate from the ECO algorithm) ensures that local cycles are eliminated (unlike with CO, which implies serializability by itself; however, practically also for CO a local concurrency mechanism is utilized, at least to ensure Recoverability). Local transactions can be always committed concurrently (even if a precedence relation exists, unlike CO). When the overall transactions' local partial order (which is determined by the local conflict graph, now only with possible temporary local cycles, since cycles are eliminated by a local serializability mechanism) allows, also global transactions can be voted on to be committed concurrently (when all their transitively (indirect) preceding (via conflict) global transactions are committed, while transitively preceding local transactions can be at any state. This in analogy to the distributed CO algorithm's stronger concurrent voting condition, where all the transitively preceding transactions need to be committed).
The condition for guaranteeing Global ECO can be summarized similarly to CO:
- The Global ECO Enforcing Vote ordering strategy Theorem
- Let T1,T2 be undecided (neither committed nor aborted) global transactions in a database system that ensures serializability locally, such that a directed path of unaborted transactions exists in the local conflict graph (that of the database itself) from T1 to T2. Then, having T1 ended (either committed or aborted) before T2 is voted on to be committed, in every such database system in a multidatabase environment, is a necessary and sufficient condition for guaranteeing Global ECO (the condition guarantees Global ECO, which may be violated without it).
Global ECO (all global cycles in the global conflict graph are eliminated by atomic commitment) together with Local serializability (i.e., each database system maintains serializability locally; all local cycles are eliminated) imply Global serializability (all cycles are eliminated). This means that if each database system in a multidatabase environment provides local serializability (by any mechanism) and enforces the vote ordering strategy in the theorem above (a generalization of CO's vote ordering strategy), then Global serializability is guaranteed (no local CO is needed anymore).
Similarly to CO as well, the ECO voting-deadlock situation can be summarized as follows:
- The ECO Voting-Deadlock Theorem
- Let a multidatabase environment comprise database systems that enforce, each, both Global ECO (using the condition in the theorem above) and local conflict serializability (which eliminates local cycles in the global conflict graph). Then, a voting-deadlock occurs if and only if a global cycle (spans two or more databases) exists in the Global augmented conflict graph (also blocking by a data-access lock is represented by an edge). If the cycle does not break by any abort, then all the global transactions on it are involved with the respective voting-deadlock, and eventually each has its vote blocked (either directly, or indirectly by a data-access lock). If a local transaction resides on the cycle, it may be in any unaborted state (running, ready, or committed; unlike CO no local commit blocking is needed).
As with CO this means that also global deadlocks due to data-access locking (with at least one lock blocking) are voting deadlocks, and are automatically resolved by atomic commitment.
Multi-version CO (MVCO)
Multi-version Commitment Ordering (MVCO; (Raz 1993b)) is a generalization of CO for databases with multi-version resources. With such resources read-only transactions do not block or being blocked for better performance. Utilizing such resources is a common way nowadays to increase concurrency and performance by generating a new version of a database object each time the object is written, and allowing transactions' read operations of several last relevant versions (of each object). MVCO implies One-copy-serializability (1SER or 1SR) which is the generalization of serializability for multi-version resources. Like CO, MVCO is non-blocking, and can be combined with any relevant multi-version concurrency control mechanism without interfering with it. In the introduced underlying theory for MVCO conflicts are generalized for different versions of a same resource (differently from earlier multi-version theories). For different versions conflict chronological order is replaced by version order, and possibly reversed, while keeping the usual definitions for conflicting operations. Results for the regular and augmented conflict graphs remain unchanged, and similarly to CO a distributed MVCO enforcing algorithm exists, now for a mixed environment with both single-version and multi-version resources (now single-version is a special case of multi-version). As for CO, the MVCO algorithm needs only (unmodified) atomic commitment protocol messages with no additional communication overhead. Locking-based global deadlocks translate to voting deadlocks and are resolved automatically. In analogy to CO the following holds:
- The MVCO and Global one-copy-serializability Theorem
- MVCO compliance of every autonomous database system (or transactional object) in a mixed multidatabase environment of single-version and multi-version databases is a necessary condition for guaranteeing Global one-copy-serializability (1SER).
- MVCO compliance of every database system is a sufficient condition for guaranteeing Global 1SER.
- Locking-based global deadlocks are resolved automatically.
- Comment: Now a CO compliant single-version database system is automatically also MVCO compliant.
MVCO can be further generalized to employ the generalization of ECO (MVECO).
Example: CO based snapshot isolation (COSI)
CO based snapshot isolation (COSI) is the intersection of Snapshot isolation (SI) with MVCO. SI is a multiversion concurrency control method widely utilized due to good performance and similarity to serializability (1SER) in several aspects. The theory in (Raz 1993b) for MVCO described above is utilized later in (Fekete et al. 2005) and other articles on SI, e.g., (Cahill et al. 2008);[8] see also Making snapshot isolation serializable and the references there), for analyzing conflicts in SI in order to make it serializable. The method presented in (Cahill et al. 2008), Serializable snapshot isolation (SerializableSI), a low overhead modification of SI, provides good performance results versus SI, with only small penalty for enforcing serializability. A different method, by combining SI with MVCO (COSI), makes SI serializable as well, with a relatively low overhead, similarly to combining the generic CO algorithm with single-version mechanisms. Furthermore, the resulting combination, COSI, being MVCO compliant, allows COSI compliant database systems to inter-operate and transparently participate in a CO solution for distributed/global serializability (see below). Besides overheads also protocols' behaviors need to be compared quantitatively. On one hand, all serializable SI schedules can be made MVCO by COSI (by possible commit delays when needed) without aborting transactions. On the other hand, SerializableSI is known to unnecessarily abort and restart certain percentages of transactions also in serializable SI schedules.
CO and its variants are transparently interoperable for global serializability
With CO and its variants (e.g., SS2PL, SCO, OCO, ECO, and MVCO above) global serializability is achieved via atomic commitment protocol based distributed algorithms. For CO and all its variants atomic commitment protocol is the instrument to eliminate global cycles (cycles that span two or more databases) in the global augmented (and thus also regular) conflict graph (implicitly; no global data structure implementation is needed). In cases of either incompatible local commitment orders in two or more databases (when no global partial order can embed the respective local partial orders together), or a data-access locking related voting deadlock, both implying a global cycle in the global augmented conflict graph and missing votes, the atomic commitment protocol breaks such cycle by aborting an undecided transaction on it (see The distributed CO algorithm above). Differences between the various variants exist at the local level only (within the participating database systems). Each local CO instance of any variant has the same role, to determine the position of every global transaction (a transaction that spans two or more databases) within the local commitment order, i.e., to determine when it is the transaction's turn to be voted on locally in the atomic commitment protocol. Thus, all the CO variants exhibit the same behavior in regard to atomic commitment. This means that they are all interoperable via atomic commitment (using the same software interfaces, typically provided as services, some already standardized for atomic commitment, primarily for the two phase commit protocol, e.g., X/Open XA) and transparently can be utilized together in any distributed environment (while each CO variant instance is possibly associated with any relevant local concurrency control mechanism type).
In summary, any single global transaction can participate simultaneously in databases that may employ each any, possibly different, CO variant (while concurrently running processes in each such database, and running concurrently with local and other global transactions in each such database). The atomic commitment protocol is indifferent to CO, and does not distinguish between the various CO variants. Any global cycle generated in the augmented global conflict graph may span databases of different CO variants, and generate (if not broken by any local abort) a voting deadlock that is resolved by atomic commitment exactly the same way as in a single CO variant environment. local cycles (now possibly with mixed materialized and non-materialized conflicts, both serializability and data-access-locking deadlock related, e.g., SCO) are resolved locally (each by its respective variant instance's own local mechanisms).
Vote ordering (VO or Generalized CO (GCO); Raz 2009), the union of CO and all its above variants, is a useful concept and global serializability technique. To comply with VO, local serializability (in it most general form, commutativity based, and including multi-versioning) and the vote order strategy (voting by local precedence order) are needed.
Combining results for CO and its variants, the following is concluded:
- The CO Variants Interoperability Theorem
- In a multi-database environment, where each database system (transactional object) is compliant with some CO variant property (VO compliant), any global transaction can participate simultaneously in databases of possibly different CO variants, and Global serializability is guaranteed (sufficient condition for Global serializability; and Global one-copy-serializability (1SER), for a case when a multi-version database exists).
- If only local (to a database system) concurrency control information is utilized by every database system (each has the generalized autonomy property, a generalization of autonomy), then compliance of each with some (any) CO variant property (VO compliance) is a necessary condition for guaranteeing Global serializability (and Global 1SER; otherwise they may be violated).
- Furthermore, in such environment data-access-locking related global deadlocks are resolved automatically (each such deadlock is generated by a global cycle in the augmented conflict graph (i.e., a voting deadlock; see above), involving at least one data-access lock (non-materialized conflict) and two database systems; thus, not a cycle in the regular conflict graph and does not affect serializability).
References
- Raz, Yoav (August 1992), "The Principle of Commitment Ordering, or Guaranteeing Serializability in a Heterogeneous Environment of Multiple Autonomous Resource Managers Using Atomic Commitment", Proceedings of the Eighteenth International Conference on Very Large Data Bases (Vancouver, Canada): pp. 292–312, http://www.vldb.org/conf/1992/P292.PDF (also DEC-TR 841, Digital Equipment Corporation, November 1990)
- Raz, Yoav (September 1994), "Serializability by Commitment Ordering", Information Processing Letters 51 (5): pp. 257–264, doi:10.1016/0020-0190(94)90005-1
- Raz, Yoav (June 2009), Theory of Commitment Ordering - Summary, http://sites.google.com/site/yoavraz2/home/theory-of-commitment-ordering, retrieved November 11, 2011
- Raz, Yoav (November 1990), On the Significance of Commitment Ordering, Digital Equipment Corporation, http://yoavraz.googlepages.com/DEC-CO-MEMO-90-11-16.pdf
- Yoav Raz (1991a): US patents 5,504,899 (ECO) 5,504,900 (CO) 5,701,480 (MVCO)
- Yoav Raz (1991b): "The Commitment Order Coordinator (COCO) of a Resource Manager, or Architecture for Distributed Commitment Ordering Based Concurrency Control", DEC-TR 843, Digital Equipment Corporation, December 1991.
- Yoav Raz (1991c): "Locking Based Strict Commitment Ordering, or How to improve Concurrency in Locking Based Resource Managers", DEC-TR 844, December 1991.
- Yoav Raz (1993a): "Extended Commitment Ordering or Guaranteeing Global Serializability by Applying Commitment Order Selectivity to Global Transactions." Proceedings of the Twelfth ACM Symposium on Principles of Database Systems (PODS), Washington, DC, pp. 83-96, May 1993. (also DEC-TR 842, November 1991)
- Yoav Raz (1993b): "Commitment Ordering Based Distributed Concurrency Control for Bridging Single and Multi Version Resources." Proceedings of the Third IEEE International Workshop on Research Issues on Data Engineering: Interoperability in Multidatabase Systems (RIDE-IMS), Vienna, Austria, pp. 189-198, April 1993. (also DEC-TR 853, July 1992)
Footnotes
- ^ a b Alan Fekete, Nancy Lynch, Michael Merritt, William Weihl (1988): Commutativity-based locking for nested transactions (PDF) MIT, LCS lab, Technical report MIT/LCS/TM-370, August 1988.
- ^ Philip A. Bernstein, Eric Newcomer (2009): Principles of Transaction Processing, 2nd Edition, Morgan Kaufmann (Elsevier), June 2009, ISBN 978-1-55860-623-4 (pages 145, 360)
- ^ a b Lingli Zhang, Vinod K.Grover, Michael M. Magruder, David Detlefs, John Joseph Duffy, Goetz Graefe (2006): Software transaction commit order and conflict management United States Patent 7711678, Granted 05/04/2010.
- ^ Hany E. Ramadan, Indrajit Roy, Maurice Herlihy, Emmett Witchel (2009): "Committing conflicting transactions in an STM" (PDF) Proceedings of the 14th ACM SIGPLAN symposium on Principles and practice of parallel programming (PPoPP '09), ISBN 978-1-60558-397-6
- ^ Christoph von Praun, Luis Ceze, Calin Cascaval (2007) "Implicit Parallelism with Ordered Transactions" (PDF), Proceedings of the 12th ACM SIGPLAN symposium on Principles and practice of parallel programming (PPoPP '07), ACM New York ©2007, ISBN 978-1-59593-602-8 doi 10.1145/1229428.1229443
- ^ Robert Kallman, Hideaki Kimura, Jonathan Natkins, Andrew Pavlo, Alex Rasin, Stanley Zdonik, Evan Jones, Yang Zhang, Samuel Madden, Michael Stonebraker, John Hugg, Daniel Abadi (2008): "H-Store: A High-Performance, Distributed Main Memory Transaction Processing System", Proceedings of the 2008 VLDB, pages 1496 - 1499, Auckland, New-Zealand, August 2008.
- ^ William Perrizo, Igor Tatarinov (1998): "A Semi-Optimistic Database Scheduler Based on Commit Ordering" (PDF), 1998 Int'l Conference on Computer Applications in Industry and Engineering, pp. 75-79, Las Vegas, November 11, 1998.
- ^ Michael J. Cahill, Uwe Röhm, Alan D. Fekete (2008): "Serializable isolation for snapshot databases", Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pp. 729-738, Vancouver, Canada, June 2008, ISBN 978-1-60558-102-6 (SIGMOD 2008 best paper award
External links
Categories:

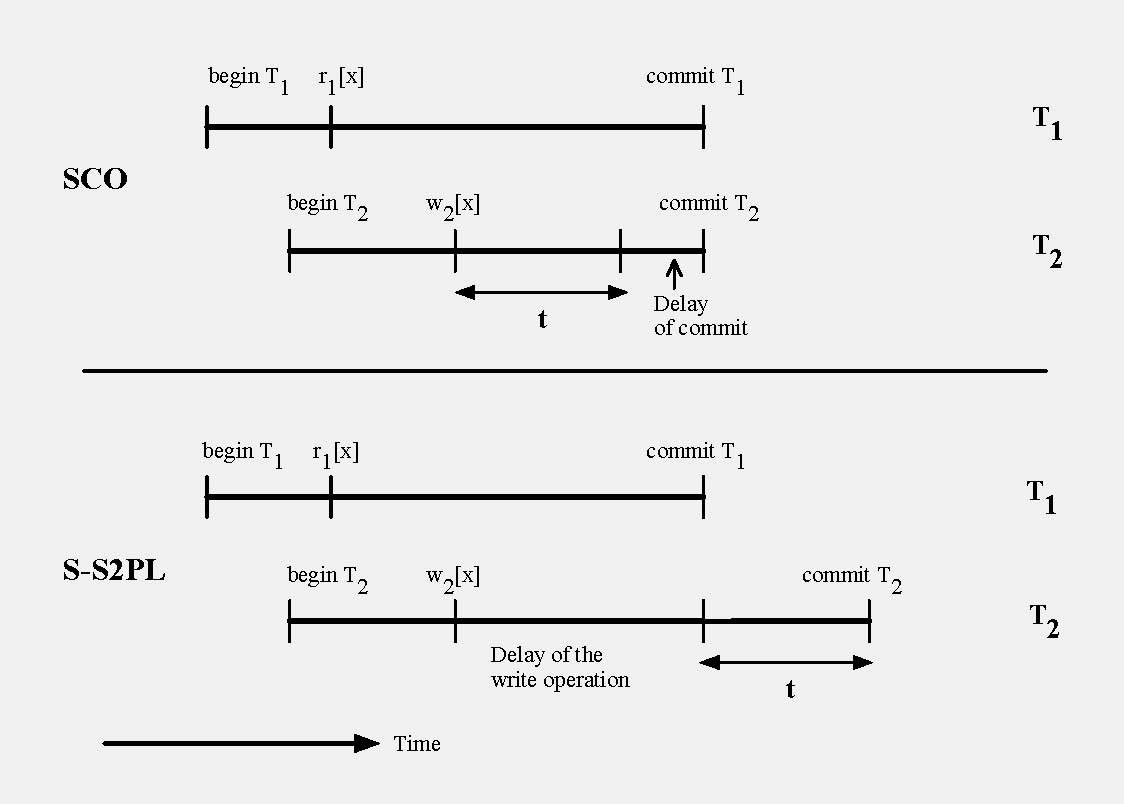
Wikimedia Foundation. 2010.