- Maintenance philosophy
-
Maintenance Philosophy is the mix of strategies that ensure an item works as expected when needed.[1][2]
Contents
Definition
Maintenance is a form of risk management that is required if and only if an item fails to satisfy the minimum level of specification performance when the items or system is required.
Maintenance is optional and may not be required if the partially failed item still satisfies the minimum level of specification performance or if the item is not required for a span of time.
Maintenance takes place in four phases.
- Failure Detection
- Fault isolation
- Corrective action
- Operational verification
An item is said to be degraded when faults exist but normal operation can continue.
Automatic recovery is used to avoid the need for maintenance.
Automatic recovery from failure is required for systems and resources that cannot be accessed during deployment, such as rockets, missiles, satellites, submersibles, and items that are buried or encapsulated. There are multiple approaches.
- Custom items designed specifically for ultra high reliability
- Redundant items with reconfiguration features that automatically bypass failure
- Lot testing to reduce manufacturing defects
Redundant items increase failure rate and reduce reliability if recovery is not automatic.
Failure Detection
Failure Detection involves two different maintenance strategies that interact with life-cycle cost and availability.
- Conditional
- Periodic
Conditional
Conditional maintenance relies on indicators that tell users when an item is failed.
- System is totally failed and cannot operate as expected
- System will function as expected but is degraded
This requires automatic fault detection and reporting.
Condition Based Maintenance (CBM) requires clearly observable or audible notification that is suitable for unsophisticated and untrained users, which includes the following.
- Colored indicator (red or yellow light)
- Display showing the phrase failed or degraded next to the item name
- Gage with clearly defined green, yellow, and red bands for normal versus faulted
- Audible indications, such as a buzzer, bell, or synthesized voice
Recovery maintenance actions begin after notification occurs.
Items are said to be instrumented when notification takes place automatically upon failure. There are two approaches.
- End-To-End (ETE)
- Self-reporting devices
ETE testing involves an automated process that periodically injects something into the item, then the outputs are examined to determine if they satisfy the level of performance required by the specification. This may be intrusive, and could interfere with normal operation briefly.
Self-reporting devices include automatic built-in-test (BIT) features that are less intrusive.
Items without the kinds of notifications suitable for CBM have silent failure modes that require periodic preventative maintenance actions.
Periodic
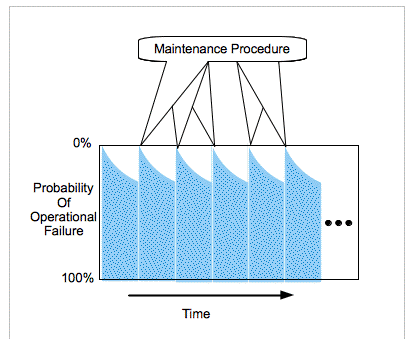
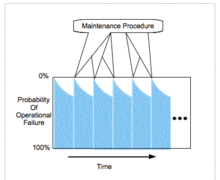 Probability of operational failure accumulates as time passes until diagnostic or preventative maintenance actions eliminate any actual failures.
Probability of operational failure accumulates as time passes until diagnostic or preventative maintenance actions eliminate any actual failures.
Operational failure will eventually occur when an item is used in its normal mode of operation if there is no intervention. The procedures associated with periodic maintenance are generally called a Periodic Maintenance System (PMS).
There is risk that the system will not work as expected, and this risk grows as time passes due to increasing possibility of silent faults that cause operational failure.
Periodic maintenance actions control risk of operational failure. This relies on invasive procedures that renders a system inoperable for a brief period while users run manual diagnostic or preventative procedures. The following are a few examples.
- Calibration
- Built In Test (BIT)
- External Diagnostics (instrumentation)
- System Operational Test (SOT)
The item is down and is unavailable for normal operation during the time while a periodic maintenance procedure is being performed.
Failure is statistical. There is a random chance that the system or item will not function when required. Reliability declines as the time passes, and probability of failure increases until action is taken.
The item will eventually fail if there is no intervention.
Periodic maintenance increasingly reduces operational failure risks as procedure are used more often. Average reliability improves as the time between maintenance actions is reduced.
As an example, an item with no CBM features will work as expected about 90% of the time if periodic maintenance is performed about 5 times more frequently than the MTBF.Fault Isolation
Fault Isolation is the strategy used to identify the root cause for a failure. There are two methods.
- Automatic Fault Isolation
- Manual Fault Isolation
Automatic Fault Isolation
Automatic Fault Isolation identifies the root cause for failure with no manual intervention.
This is generally used to control redundant items when it is necessary to automatically bypass failures.
Manual Fault Isolation
Manual Fault Isolation is when maintenance personnel must identify root cause for a failure. This usually requires the following.
- Manual diagnostic tests
- Test equipment
- Spare parts
- Documentation
- Training
Device instrumentation used with CBM is generally used to reduce the time and effort required to isolate root cause.
Corrective Action
Corrective Action is the activity that restores performance for the item or system after a failure.
There are two kinds of corrective action.
- Automatic
- Manual
Automatic Corrective Action
Automatic correction is possible for redundant systems when fault-detection, fault-isolation, and fault-bypass are all automatic.
Automatic corrective action is also called Active Recovery and Self Healing.
This technique can be used to increase the MTBF to the length of time an item will be required to be used without maintenance.
As an example, failure is expected for space vehicles that can be required to operate correctly for as much as 10 years in a hostile environment.
Redundancy can be achieved by launching a large number of satellites, which is a practical solution for things like the Global Positioning System (GPS) because each vehicle occupies a slightly different orbit.
This is not possible for geosynchronous orbit, where all functions must be accomplished by one vehicle that performs all functions must maintain stable position over one specific spot over the earth surface. Satellites intended to operate in geosynchronous orbit must incorporate active recovery that prevents total failure when one or more parts fail.
Automatic Corrective Action incorporates all of the spare parts into the design to accommodate all of the failures that can be anticipated during a specific period of time.
Manual Corrective Action
Manual corrective action is when trained maintenance personnel perform a calibration or replacement action to restore operation.
Corrective actions for redundant items includes manual reconfiguration when automatic fault bypass is not available, which depends upon maintenance coverage.
Failed part replacement depends upon the Lowest Replaceable Unit (LRU). This could be a part inside an item, or it could be the whole item. This decision is made based on which is less expensive to replace.
As an example, a new disk drive costs about $200 to purchase, the technical assistance to replace the disk drive is $500, and a refurbished computer costs about $600. If you replace your own disk drive and install your own operating system, then it is less expensive to purchase the disk drive. If you need technical help then it is less expensive to replace the whole computer.
Operational Verification
Operational Verification is any action that is performed to verify that the item or system is operational.
This generally involves using the system in its normal mode of operation, which could involve actual operation or simulated operation.
Reliability
Maintenance is closely associated with reliability because maintenance is required to restore capability that has been lost due to failure.
Electronic devices decay in a way that is mathematically equivalent to radioactive decay processes for unstable atoms.
Electronic failure is governed by random processes, where Mean Time Between Failure identifies the average number of hours until failure occurs. Lambda λ identifies the number of failures expected per hour.
Reliability is the probability that a failure will not occur during a specific span of time.
Failure rate relies on logarithmic math to simplify calculations using λ that is very similar to the type of analysis used for electronic circuits.Overall failure rate for a complex item is the sum of all the failure rates for all of the individual components in the item. This applies to situations where failure of one component causes the entire item to fail. The type of calculation is similar to a series electronic circuit.
Overall failure rate for items with full redundant overlap is the inverse of the sum of MTBF for all of the individual redundant items. This applies to situations where all of the components in the item must all fail before the item fails. The type of calculation is similar to a parallel electronic circuit.
A reliability block diagram is used to construct a model for large items. This provides traceability when funding and manpower requirements are identified using reliability calculations.Failure rate for silicon and carbon devices doubles for each 5oC temperature rise. Electronic devices operating at 60oC will fail 64 times more frequently than the same kind of items operating at 30oC. This relationship holds true above 25oC.
Transportation reliability is similar, but values are expressed in terms of distance, such as fault per mile or faults per kilometer.
Failure rate can is be expressed in terms of the number of cycles. Thermal shock caused by heating and cooling can induce failure when power is cycled on and off. Most mechanical switches are built to operate 10,000 cycles before failure, which is about 30 years for a cycle rate of 1 action per day.
Distance, cycle, and decay reliability all have separate contributions that effect the overall failure rate.
Availability
Availability is generally used with systems that incorporate periodic maintenance.
Availability is the probability that an item will operate correctly during a period of time when used at random times during that period.
Available time is the time while the system is fully operational. Down time is the time while the system is unavailable for normal use, and this consist of the time while periodic maintenance is being performed and the amount of time while the system is faulted.Availability calculations are meaningful for items with replaceable parts only when failure modes have adequate coverage.
-
- Coverage > Availability
Readiness
Readiness is meaningful when the item does not require down time for periodic maintenance. This is a useful measurement for items that incorporate automatic recovery or condition based maintenance.
Readiness is the probability that an item will operate as expected when used at any random time while the item is in the correct mode of operation.
Mean Time To Recover form manual actions is generally measured or estimated. The following is an example of the kind of values that could be used for estimating the mechanical portion of the recovery time associated with replacing a failed circuit card.- Static wrist strap
- 120 seconds
- Bolts and screws with captive nut
- remove 15 seconds; replace 30 seconds
- Bolts and screws with loose nut
- remove 30 seconds; replace 60 seconds
- Small cables
- disconnect 15 seconds; reconnect 60 seconds
- Circuit card
- remove 30 seconds; insert 120 seconds
Readiness calculations are meaningful for items with replaceable parts only when failure modes have adequate coverage.
-
- Coverage > Readiness
Coverage
Maintenance coverage evaluates the proportion of faults detected by CBM and PMS.
A rough estimate of coverage can be made by observing the ratio between operational failures and maintenance actions.
Availability calculations, readiness calculations, and related claims are only valid if coverage exceeds availability.Military Versus Commercial
 Military maintenance philosophy versus commercial.
Military maintenance philosophy versus commercial.Military systems and large commercial systems share reliability constraints.
The ability to for a military system to continue operating after battle damage is survivability.
Military Maintenance Policy (MMP) is required for defense systems. Designs typically include redundancy with automatic fault detection, automatic fault isolation, and automatic fault bypass. These reconfigure systems without human intervention after combat damage and normal failure.
Most Commercial Off The Shelf (COTS) items are deployed in a benign environment, but electronic devices fail much like constant random battle damage. This effect grows worse as size grows.
Excessive down-time is a type of design defect that impacts all large systems.
As an example, if a system is built from 1,000 individual computers each with a 3 year Mean Time Between Failure (MTBF), then the whole system will have an MTBF of 1 day. If Mean Time To Repair (MTTR) is 3 days, then the system will never work.
If the same system includes 1,010 computers, then failure will be rare if the system includes automatic fault detection, automatic fault isolation, and automatic fault bypass.
This shows why large commercial systems require the same kind of maintenance philosophy as military systems.
See also
External links
- OPNAV Instruction 4790.13A, Maintenance of Surface Ship Electronic Equipment, Department of the Navy
- OPNAV Instruction 4790.4E, Ships' Maintenance and Material Management (3-M) System Policy, Department of the Navy (periodic maintenance)
- OPNAV Instruction 4790.16A, Condition-Based Maintenance Policy, Department of the Navy
- OPNAV Instruction 4700.7L, Maintenance Policy For United States Navy Ships, Department of the Navy
- OPNAV Instruction 3000.12A, Operational Availability Of Equipments And Weapons Systems, Department of the Navy
- OPNAV Instruction 3500.39C, Operational Risk Management, Department of the Navy
- OPNAV Instruction 3501.316B, Policy For Baseline Composition And Basic Mission Capabilities Of Major Afloat Navy And Naval Groups, Department of the Navy
- OPNAV Instruction 3501.383, Fleet Readiness Reporting Guidance, Department of the Navy
- OPNAV Instruction 8000.16C, Naval Ordnance Maintenance Management Program, Department of the Navy
- [http://doni.daps.dla.mil/Directives/09000%20General%20Ship%20Design%20and%20Support/09-00%20General%20Ship%20Design%20Support/9070.1.pdf
OPNAV Instruction 9070.1, Survivability Policy For Surface Ships Of The U.S. Navy, Department of the Navy]
References
- ^ "New Reliability Policy Issued". Defense Acquisition University. https://dap.dau.mil/career/log/blogs/archive/2011/03/25/new-reliability-policy-issued.aspx.
- ^ "DoN Issuances". Department of the Navy. http://doni.daps.dla.mil/.
Categories:














Wikimedia Foundation. 2010.